


生成的AI在平衡自主權和可控性方面面臨著關鍵的挑戰。儘管自主性通過強大的生成模型取得了顯著提高,但可控性已成為機器學習研究人員的焦點。基於文本的控制已變得尤為重要,因為自然語言提供了人類和機器之間的直觀界面。這種方法啟用了圖像編輯,音頻綜合和視頻生成的傑出應用程序。最近的文本到數據生成模型,尤其是使用擴散技術的模型,通過利用廣泛的數據文本對數據集的語義洞察顯示出了令人印象深刻的結果。但是,在低資源情況下,由於復雜的數據結構而獲得足夠的文本配對數據變得昂貴或複雜,因此出現了重大障礙。諸如分子數據,運動捕獲和時間序列之類的關鍵領域通常缺乏足夠的文本標籤,這限制了監督的學習能力並阻礙了先進的生成模型的部署。這些局限性可以預見,導致發電質量差,模型過度擬合,偏見和有限的輸出多樣性,在優化文本表示方面存在很大的差距,以在數據限制的環境中更好地對齊。
低資源場景促使了幾種緩解方法,每種方法都有固有的局限性。數據增強技術通常無法準確地使合成數據與原始文本描述和風險過高,同時增加了擴散模型中的計算需求。半監督的學習與文本數據中固有的歧義鬥爭,在處理未標記的樣本時,正確的解釋挑戰。轉移學習雖然有限的數據集有望,但經常遭受災難性遺忘,該模型在適應新的文本描述時失去了以前獲得的知識。這些方法論上的缺點突出了對在低資源環境中專門為文本到數據專門設計的更健壯方法的必要性。
在本文中,Salesforce AI研究的研究人員在場 text2data 這引入了基於擴散的框架,該框架通過兩階段的方法在低資源場景中增強文本到數據可控性。首先,它通過無標記的數據通過無監督的擴散模型來掌握數據分佈,從而避免了半監督方法中常見的語義歧義。其次,它在不擴展培訓數據集的情況下對文本標記的數據進行可控的微調。取而代之的是,Text2Data採用了一個基於約束優化的學習目標,該目標通過使模型參數接近其預先調節狀態來防止災難性遺忘。這個獨特的框架有效地利用了標記和未標記的數據來維持精細的數據分佈,同時實現了卓越的可控性。理論驗證支持優化約束選擇和泛化界限,與基線方法相比,三種模式的全面實驗證明了Text2Data的出色發電質量和可控性。
Text2DATA通過學習條件分佈Pθ(X | C)來解決可控的數據生成,其中有限的配對數據會引起優化挑戰。該框架以兩個不同的階段運行,如下圖所示。最初,它利用更豐富的未標記數據來學習邊際分佈pθ(x),在集合θ中獲得最佳參數θ。這種方法利用了邊際和條件分佈之間的數學關係,其中Pθ(x)近似於文本分佈的Pθ(x | c)的期望值。隨後,在實現約束優化時,使用可用標記的數據文本對進行Text2Data微調這些參數,以保持更新的參數θ̂“在θ和θ的交集中。該約束確保模型在獲得文本可控性的同時保持對總體數據分佈的了解,從而有效防止災難性忘記通常在微調過程中發生。
Text2Data首先將所有可帶有空代幣的可用數據作為條件來學習一般數據分佈,從而實現了其兩階段方法。這允許模型優化Pθ(x |∅),該模型有效地等於pθ(x),因為零令牌與x無關。第二階段引入了一個約束優化框架,該框架可以在文本標記的數據上微調模型,同時阻止參數從先前學習的分佈中漂移。從數學上講,這表示是將有條件的概率Pθ(x | c)的負模擬樣本最小化,即受到邊際分佈性能保持接近在第一階段建立的最佳值ξ的約束。這種基於約束的方法通過確保模型參數保留在最佳集合中,直接解決了災難性的遺忘,在該集合中,通用數據表示和特定於文本的可控性都可以共存 – 實際上解決了平衡這些競爭目標的詞典優化問題。
它通過將理論目標轉換為實際損失函數來實現無分類器擴散指導。該框架優化了三個關鍵組件:用於一般數據分佈學習的L1(θ),l’1(θ)用於標記數據的分佈保護,而文本條件生成的L2(θ)。使用可用的數據樣本在經驗上估算了這些。在算法1中詳細介紹的詞素優化過程通過動態調整梯度更新與執行約束的參數λ來平衡這些目標,同時允許有效學習。該方法使用複雜的更新規則,其中根據兩個目標的梯度的加權組合對θ進行了修改。可以在訓練期間放寬約束以改善收斂性,因為認識到參數不必是原始參數空間的確切子集,但應保持近端以保持分佈知識,同時獲得可控性。

Text2Data通過驗證參數選擇的概括界限為其約束優化方法提供了理論基礎。該框架確定從擴散過程中得出的隨機變量是次高斯,從而實現了嚴格的置信度界限。定理0.2提供三個關鍵保證:首先,置信界內的經驗參數集完全包含真正的最佳集合;其次,經驗解決方案與主要目標的理論最佳有效競爭。第三,經驗解決方案保持了合理的遵守理論約束。實際實現引入了一個放鬆參數ρ,該參數調整了約束的嚴格性,同時將其保持在數學上合理的置信區間。這種放鬆確認了現實的條件,即獲得許多未標記的樣品是可行的,即使在處理具有數百萬個參數的模型時,置信度也很緊密。具有45,000個樣品和1400萬參數的運動產生的實驗證實了該框架的實際生存能力。

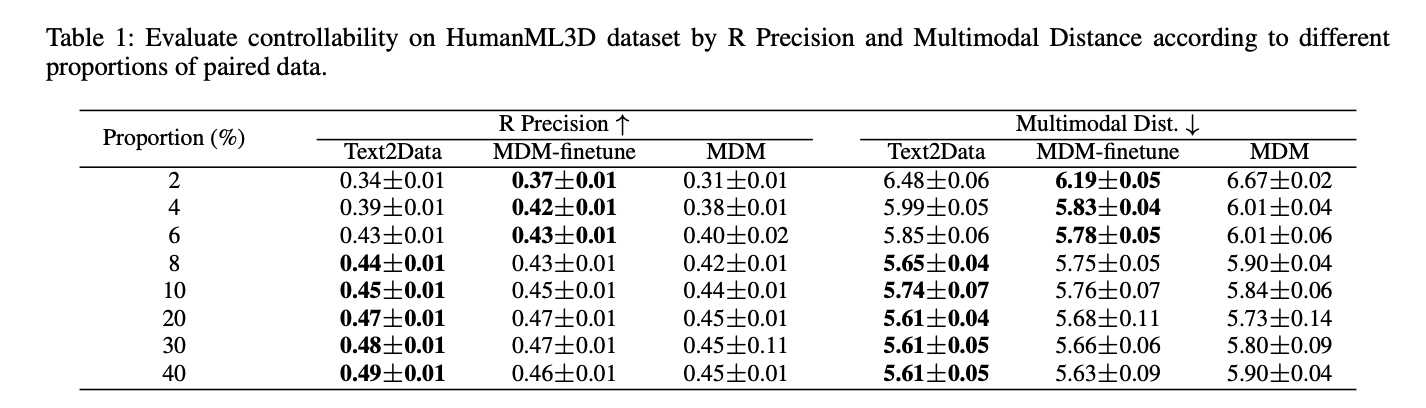
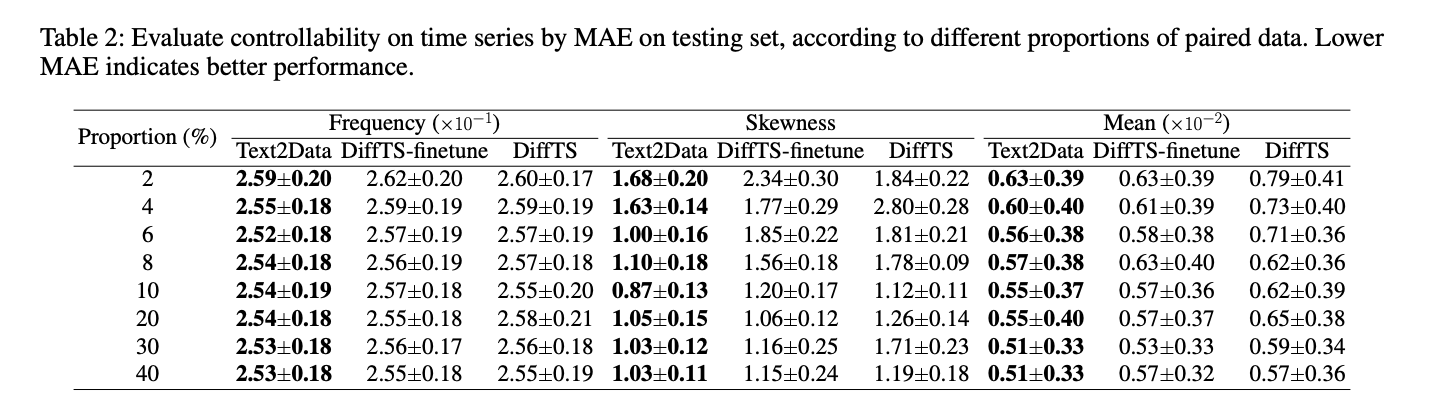
與基線方法相比,Text2DATA證明了多個領域的卓越可控性。在分子產生中,與EDM-Finetune和EDM相比,所有屬性的平均絕對誤差(MAE)較低,尤其是在ϵlumo和CV等屬性中尤其出色。對於運動產生,Text2DATA以r精度和多模式距離指標超過MDM-FINETUNE和MDM。在時間序列的生成中,它始終優於所有評估特性的差異至前和差異。除了可控性之外,Text2Data還保持出色的發電質量,顯示了分子有效性,穩定性,運動產生多樣性和時間序列中的分配對準的改善。這些結果證明了Text2Data在緩解災難性遺忘的同時,在保持發電質量的同時的有效性。

text2data 有效地解決了多種模式的低資源場景中文本到數據生成的挑戰。通過最初利用未標記的數據來掌握整體數據分佈,然後在標記數據進行微調期間實現約束優化,該框架成功地平衡了可控性與分佈保護。這種方法可防止災難性的遺忘,同時保持發電質量。實驗結果始終證明了Text2Data在可控性和發電質量方面的優越性優於基線方法。儘管通過擴散模型實現,但Text2Data的原理可以很容易地適應其他生成架構。
查看 紙和github頁面。 這項研究的所有信用都歸該項目的研究人員。另外,請隨時關注我們 嘰嘰喳喳 而且不要忘記加入我們的 80k+ ml子列數。
🚨 Meet Parlant:LLM優先的對話AI框架,旨在為開發人員提供對AI客戶服務代理商所需的控制和精確度,並利用行為指南和運行時監督。 🔧🎛️它是使用Python和TypeScript📦中易於使用的CLI📟和本機客戶sdks操作的。
Asjad是Marktechpost的實習顧問。他正在Kharagpur印度理工學院的機械工程學領域掌握B.Tech。 Asjad是一種機器學習和深度學習愛好者,他一直在研究醫療保健中機器學習的應用。
PARLANT:使用LLMS💬💬(晉升)建立可靠的AI AI客戶面對面的代理商


