


Модели глубокого обучения, революционизированные области компьютерного зрения и обработки естественного языка, становятся менее эффективными, поскольку они увеличивают сложность и связаны в большей степени за счет пропускной способности памяти, чем чистой мощности обработки. Последние графические процессоры борются с огромными ограничениями полосы пропускания, поскольку они постоянно необходимы для перемещения данных между различными уровнями памяти. Этот процесс замедляет вычисления и увеличивает потребление энергии. Задача состоит в том, чтобы разработать методы, которые минимизируют ненужные передачи данных при максимизации вычислительной пропускной способности повышения обучения и эффективности вывода.
Основной проблемой в глубоком обучении является оптимизация движения данных в архитектурах графических процессоров. Хотя графические процессоры обеспечивают огромную мощность обработки, их производительность часто ограничивается пропускной способностью, необходимой для передачи памяти, а не их вычислительных возможностей. Текущие рамки глубокого обучения изо всех сил пытаются устранения этой неэффективности, что приводит к медленному выполнению модели и высоким затратам на энергию. Флэндиация ранее продемонстрировала улучшение производительности за счет сокращения избыточного движения данных, но существующие методы в значительной степени зависят от ручной оптимизации. Отсутствие автоматического, структурированного подхода к оптимизации рабочей нагрузки графических процессоров остается основным препятствием в полевых условиях.
Существующие методы, такие как вспышка, сгруппированное внимание на запрос, квлажнение и квантование, направлены на снижение затрат на передачу памяти при сохранении вычислительной эффективности. Например, Flashattunition уменьшает накладные расходы, выполняя операции ключей в локальной памяти, устраняя ненужные промежуточные передачи данных. Тем не менее, эти методы традиционно требуют ручной оптимизации, адаптированной для конкретного оборудования. Некоторые автоматизированные подходы, такие как Triton, существуют, но еще не достигли уровней производительности решений, настроенных вручную. Спрос на систематический и структурированный подход к развитию алгоритмов глубокого обучения, достигающих память, остается нереализованным.
Университетский колледж Лондон и Массачусетские технологические науки внедрили схематический подход для оптимизации вычислений глубокого обучения. Их метод расширяет нейронные схемы для учета использования ресурсов графического процессора и распределения иерархической памяти. Визуализируя вычислительные шаги, этот метод обеспечивает систематический вывод оптимизаций с учетом графических процессоров. Исследователи предлагают структуру, которая упрощает алгоритмический дизайн, предоставляя структурированную методологию для моделирования производительности. Подход фокусируется на минимизации движения данных, оптимизации стратегий выполнения и использовании аппаратных функций для достижения высокой вычислительной эффективности.
В предлагаемой методологии используется иерархическая система схемы, которая моделирует передачи данных на разных уровнях памяти графических процессоров. Эта структура позволяет исследователям разбить сложные алгоритмы на структурированные визуальные представления, что позволяет идентифицировать избыточные движения данных. Исследователи могут получить стратегии потоковой передачи и плитки, которые максимизируют пропускную способность путем перераспределения и реструктуризации вычислений. Схематический подход также учитывает квантование и многоуровневые структуры памяти, что делает его применимым в разных архитектурах GPU. Структура обеспечивает научную основу для оптимизации графического процессора, помимо специальной настройки производительности.
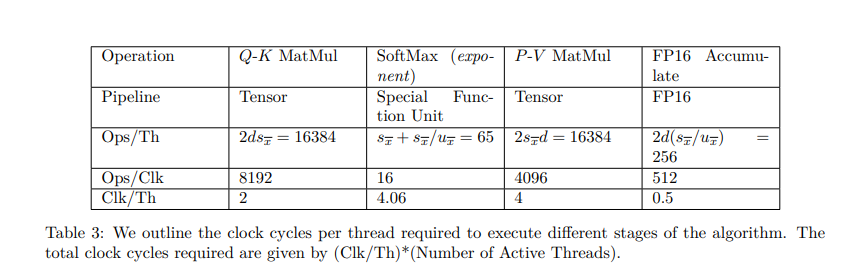
Исследование демонстрирует, что схематический подход значительно повышает производительность за счет снижения неэффективности переноса памяти. Flashattention-3, оптимизированный с использованием этого метода, достигает 75% улучшения скорости вперед на более новом оборудовании. Исследование показывает, что использование структурированных диаграмм для оптимизации с учетом графических процессоров обеспечивает высокую эффективность, при этом эмпирические результаты подтверждают эффективность подхода. В частности, FP16 Flashattention-3 достигает 75% использования своей максимальной теоретической эффективности, в то время как FP8 достигает 60%. Эти результаты подчеркивают потенциал оптимизации на основе диаграмм для повышения эффективности памяти и вычислительной пропускной способности в глубоком обучении.
Это исследование вводит структурированную структуру для глубокой оптимизации обучения, сосредоточив внимание на минимизации накладных расходов на передачу памяти, одновременно повышая вычислительные характеристики. Предложенный метод обеспечивает систематическую альтернативу традиционным подходам ручной оптимизации. Исследователи могут лучше понять аппаратные ограничения и разработать эффективные алгоритмы, используя диаграмму моделирования. Результаты показывают, что структурированная оптимизация графических процессоров может значительно повысить эффективность глубокого обучения, проложив путь для более масштабируемых и высокопроизводительных моделей искусственного интеллекта в реальных приложениях.
Проверить бумага. Весь кредит на это исследование направлено на исследователей этого проекта. Кроме того, не стесняйтесь следить за нами Twitter И не забудьте присоединиться к нашему 80K+ ML SubredditПолем
🚨 Познакомьтесь с «Партаном»: разговорная структура ИИ, на первом месте LLM, предназначенную для того, чтобы предоставить разработчикам контроль и точность, которые им нужны, по сравнению с их агентами по обслуживанию клиентов AI, используя поведенческие руководящие принципы и надзор за время выполнения. 🔧 🎛 Он работает с использованием простого в использовании CLI 📟 и нативных SDK клиента в Python и TypeScript 📦.
Нихил – стажер консультант в Marktechpost. Он получает интегрированную двойную степень в области материалов в Индийском технологическом институте, Харагпур. Нихил является энтузиастом AI/ML, который всегда исследует приложения в таких областях, как биоматериалы и биомедицинская наука. С большим опытом в области материальной науки, он изучает новые достижения и создает возможности для внесения вклад.
Парган: строите надежные агенты, обращенные к клиенту AI с LLMS 💬 ✅ (повышен)

