視覺編程在計算機視覺和AI中出現了強烈的出現,尤其是在圖像推理方面。 Visual編程使計算機可以創建可執行的代碼,以與視覺內容進行交互以提供正確的響應。這些系統構成了對象檢測,圖像字幕和VQA應用程序的主幹。它的有效性源於模塊化多個推理任務的能力,但正確性提出了一個重大問題。與常規編程相反,在語法檢查和調試過程中可以檢測到邏輯錯誤,視覺程序會產生看似正確的結果,但在邏輯上可能是不正確的。改進的單元測試方法在使其更可靠的過程中起著至關重要的作用。
視覺編程的一個反復出現的問題是,出於錯誤的原因,模型給出了正確的答案。無法驗證這些輸出的邏輯具有嚴重的影響,因為在遭受新數據時,表現出色的程序突然會意外失敗。 Codellama-7B模型針對GQA數據集生成的100個視覺程序的最新研究表明,這些程序中只有33%是正確的。另一方面,需要重寫23%的人。大多數模型基於統計相關性而不是實際理解,因此容易受到邊緣情況的影響。視覺編程缺乏系統的測試程序,錯誤往往沒有引起注意,並且需要更強大的驗證框架。
提高視覺程序可靠性的努力主要集中於使用標記的數據集進行培訓,但是這種方法有局限性。培訓數據的註釋可能很昂貴,並且可能無法涵蓋所有潛在用例。一些研究人員探索了強化學習策略,優先考慮計劃在培訓期間產生正確答案的計劃,但是這些方法並不一定能確保邏輯合理性。廣泛用於基於文本的編程的傳統單元測試已被調整以檢查程序輸出是否屬於預定義的類別。儘管這些方法提供了一定的驗證水平,但它們並未驗證答案背後的原因在邏輯上是否正確。解決這些限制需要係統評估程序行為的新解決方案。
Salesforce AI研究和賓夕法尼亞大學的研究人員介紹了 視覺單元測試(viunit),旨在通過生成評估邏輯正確性的單元測試來提高視覺程序的可靠性的框架。與主要用於基於文本的應用程序中的常規單元測試技術不同,Viunit在圖像解答對中生成了測試用例。這些單元測試使研究人員能夠驗證模型是否真正了解圖像中的關係和屬性,而不是依靠統計快捷方式。該框架背後的核心思想是通過創建用作測試輸入的圖像來系統地評估視覺程序,並附有該程序應生成的預期答案。此過程確保模型產生正確的答案並遵循邏輯步驟以達到它們。
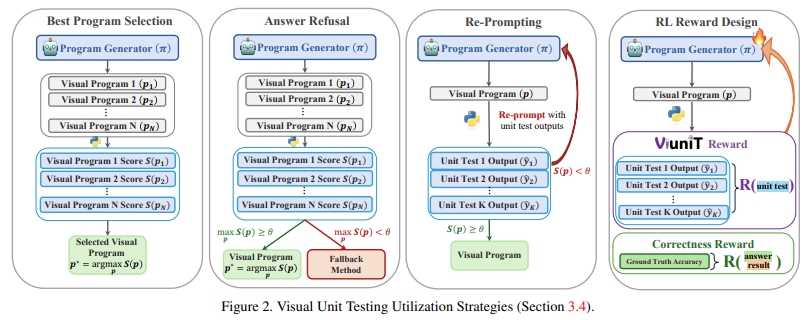
Viunit框架利用LLMS生成測試用例。此過程始於創建候選圖像描述,然後使用最先進的文本對圖像生成模型將其轉換為綜合圖像。為了最大程度地提高單元測試的有效性,Viunit合併了一個優化標準,該標準選擇圖像描述,為不同方案提供最佳的測試覆蓋範圍。然後,系統在這些測試圖像上執行視覺程序,將程序的響應與預期答案進行比較。評分功能用於評估程序在這些測試上的表現,並且可以將測試失敗的程序進行完善或丟棄。這種結構化方法可確保單位測試是全面的,並且可以確定廣泛的潛在錯誤。該框架還介紹了可視單元測試的四個關鍵應用程序:最佳程序選擇,拒絕,重新提出和基於強化學習的獎勵設計。這些應用程序允許研究人員通過選擇表現最佳的程序來提高模型可靠性,拒絕在信心低時產生答案,通過迭代提示來完善程序,並使用單位測試驅動的增強加固學習進行培訓模型。
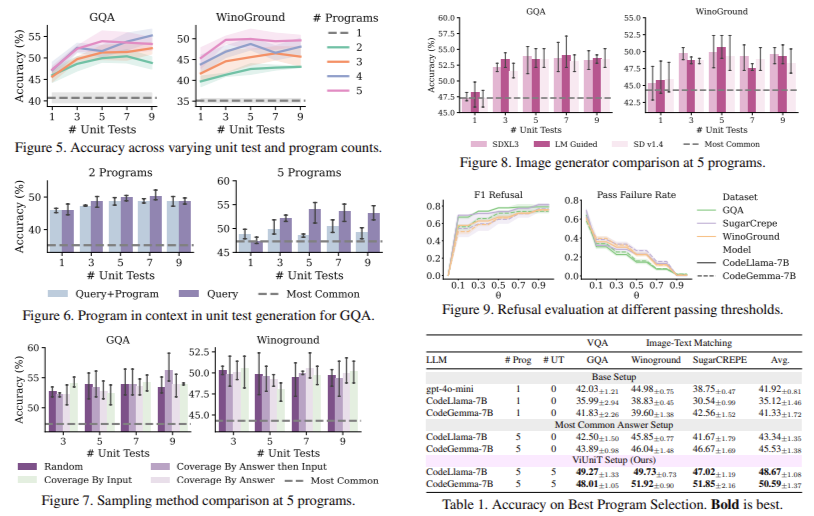
為了評估Viunit,研究人員在三個數據集(GQA,糖篩和Winoground)上進行了廣泛的實驗,這些實驗是用於評估視覺推理和圖像文本匹配的常用基準。結果表明,Viunit顯著提高了模型性能。具體而言,在所有數據集中,它平均提高了準確性11.4%。該框架還允許具有70億個參數的開源模型勝過諸如GPT-4O-MINI(平均)7.7%(例如GPT-4O-MINI)。此外,Viunit由於錯誤原因而成功地減少了正確的程序數量。在Viunit中實施的基於增強學習的獎勵設計被證明是高效,表現優於傳統的基於正確性的獎勵策略。該改進表明單位測試可用於檢測錯誤以及積極完善和改善模型性能。引入答案拒絕策略也有助於可靠性,確保模型不會以低信心提供誤導性的回答。
研究的幾個關鍵要點包括:
- GQA中只有33%的經過測試的視覺程序是完全正確的,而由於邏輯缺陷,23%需要大量重寫。
- Viunit將邏輯上有缺陷的程序減少了40%,以確保模型依靠合理的推理而不是統計快捷方式。
- 在三個數據集中,該框架的平均模型準確性平均提高了11.4%。
- Viunit啟用了7B開源型號,以勝過GPT-4O-Mini 7.7%。
- 該框架介紹了四個新穎的應用程序 – 最佳計劃選擇,答案拒絕,重新提出和強化學習獎勵設計。
- 與基於錯誤的重新提交相比,基於Viunit的重新提高的重新提高的性能提高了7.5個百分點。
- Viunit中使用的強化學習策略優於基於正確性的獎勵策略,提高了1.3%。
- 該系統在程序不可靠時成功確定,改善答案拒絕策略並減少虛假信心。
查看 紙和github頁面。 這項研究的所有信用都歸該項目的研究人員。另外,請隨時關注我們 嘰嘰喳喳 而且不要忘記加入我們的 80k+ ml子列數。
🚨 推薦的閱讀-LG AI研究釋放Nexus:一個高級系統集成代理AI系統和數據合規性標準,以解決AI數據集中的法律問題
Marktechpost的諮詢實習生,IIT Madras的雙學位學生Sana Hassan熱衷於應用技術和AI來應對現實世界中的挑戰。他對解決實踐問題的興趣非常興趣,他為AI和現實生活中的解決方案的交集帶來了新的視角。
🚨推薦開源AI平台:“ Intellagent是一個開源的多代理框架,可評估複雜的對話AI系統”(已晉升)