LG AI研究最近的一篇論文表明,據說用於培訓AI模型的“開放”數據集可能會提供錯誤的安全感 – 發現在五個AI數據集中,近四個被標記為“商業上使用”的數據集實際上包含隱藏的法律風險。
這些風險範圍從包含未公開的受版權保護材料到埋在數據集依賴關係深處的限制性許可條款。如果本文的發現是準確的,那麼依靠公共數據集的公司可能需要重新考慮其當前的AI管道,或者在下游法律曝光。
研究人員提出了一種根本性且潛在的有爭議的解決方案:基於AI的合規代理,能夠比人類律師更快,更準確地掃描和審核數據集歷史。
論文指出:
“本文主張,不能完全通過審查表面級許可條款來確定AI培訓數據集的法律風險;對數據集重新分佈進行徹底的端到端分析對於確保合規性至關重要。
“由於這種分析由於其複雜性和規模而超出了人類的能力,因此AI代理可以通過更高的速度和準確性來彌合這一差距。沒有自動化,關鍵的法律風險在很大程度上仍未受到檢查,這危害道德AI的發展和監管依從性。
“我們敦促AI研究界將端到端的法律分析視為基本要求,並採用AI驅動的方法作為可伸縮數據集合的可行途徑。”
研究2,852個受歡迎的數據集,這些數據集根據其單獨的許可而在商業上使用,研究人員的自動化系統發現,一旦所有組件和依賴項都被追踪,實際上只有605個(約21%)在法律上是安全的商業化。
新論文的標題為 請勿信任您看到的許可證 – 數據集合規則需要大規模的AI驅動生命週期跟踪,並且來自LG AI研究的八名研究人員。
權利和錯誤
作者強調了在越來越不確定的法律景觀中推動AI開發的公司所面臨的挑戰 – 因為圍繞數據集培訓的前學術“合理使用”心態讓位於不清楚法律保護的破碎環境中,而不再保證安全港。
正如一個出版物最近指出的那樣,公司對其培訓數據的來源變得越來越防禦。作者Adam Buick評論*:
“(而Openai)披露了GPT-3的主要數據來源,該論文介紹了GPT-4 揭示 只有培訓模型的數據才是“公開可用數據(例如Internet數據)和從第三方提供商許可的數據的混合”。
“AI開發人員在任何細節上都沒有闡明這種轉變的動機,而在許多情況下,他們根本沒有任何解釋。
“就其部分而言,Openai證明了其決定不根據“競爭格局和大規模模型的安全含義”的擔憂發布有關GPT-4的更多細節,而報告中沒有進一步的解釋。
透明度可能是一個不明智的術語,也可以是錯誤的術語;例如,Adobe的旗艦螢火蟲生成模型接受了Adobe有權利用的股票數據培訓,據說向客戶保證了他們使用該系統的合法性。後來,有一些證據表明,螢火蟲數據鍋已經“豐富”了其他平台的受版權保護的數據。
正如我們在本週早些時候討論的那樣,旨在確保數據集中的許可證合規性的越來越多的計劃,其中包括只能使用靈活的Creative Commons許可證刮擦YouTube視頻。
問題在於,正如新研究所表明的那樣,這些許可本身可能是錯誤的,也可能是錯誤的。
檢查開源數據集
當上下文不斷變化時,很難開發一個評估系統,例如作者的聯繫。因此,本文指出,Nexus數據合規性框架系統基於“此時的各種先例和法律理由”。
Nexus利用AI驅動的代理稱為 自動遵守 用於自動數據合規性。自動符號由三個關鍵模塊組成:用於Web探索的導航模塊;提出信息提取的提問(QA)模塊;以及法律風險評估的評分模塊。
自動符號從用戶提供的網頁開始。 AI提取關鍵細節,搜索相關資源,確定許可條款和依賴項,並分配法律風險評分。資料來源:https://arxiv.org/pdf/2503.02784
這些模塊由微調的AI模型提供動力,包括經過合成和人體標記數據訓練的Exaone-3.5-32b-Instruct模型。自動符合性還使用數據庫來緩存結果以提高效率。
自動符號從用戶提供的數據集URL開始,並將其視為根實體,搜索其許可條款和依賴項,然後遞歸跟踪鏈接的數據集以構建許可證依賴關係圖。映射所有連接後,它將計算合規性分數並分配風險分類。
新作品中概述的數據合規框架標識了各種† 數據生命週期中涉及的實體類型,包括 數據集,這構成了AI培訓的核心輸入; 數據處理軟件和AI模型,用於轉換和利用數據;和 平台服務提供商,有助於數據處理。
該系統通過考慮這些各種實體及其相互依賴性來整體評估法律風險,而不是對數據集許可證的死記硬背評估,以包括參與AI開發的組件的更廣泛的生態系統。
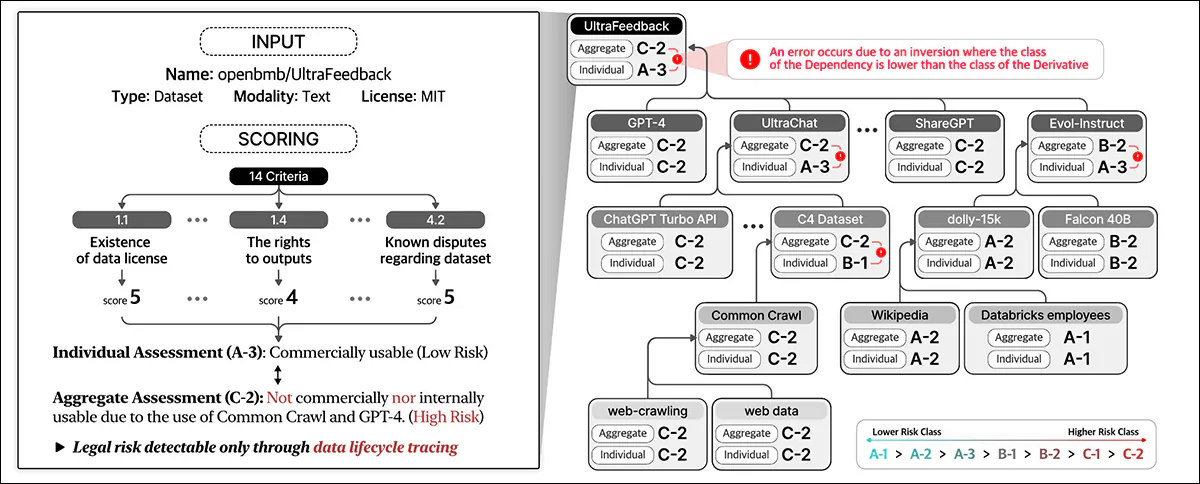
數據合規性評估整個數據生命週期中的法律風險。它根據數據集詳細信息和14個標準分配得分,對各個實體進行分類並跨依賴項匯總風險。
培訓和指標
作者在擁抱面上提取了前1,000名最下載的數據集的URL,隨機地採樣216個項目以構成測試集。
Exaone模型在作者的自定義數據集上進行了微調,並使用合成數據進行導航模塊和問題吸收模塊,並使用人體標記的數據進行評分模塊。
地面真相標籤是由五位在類似任務中培訓至少31個小時的法律專家創建的。這些人類專家手動確定了216例測試案例的依賴項和許可條款,然後通過討論匯總並完善了他們的發現。
通過針對Chatgpt-4O和困惑Pro的經過訓練的,經過訓練的人為校準的自動符號系統,在許可證術語中發現了更多的依賴性:
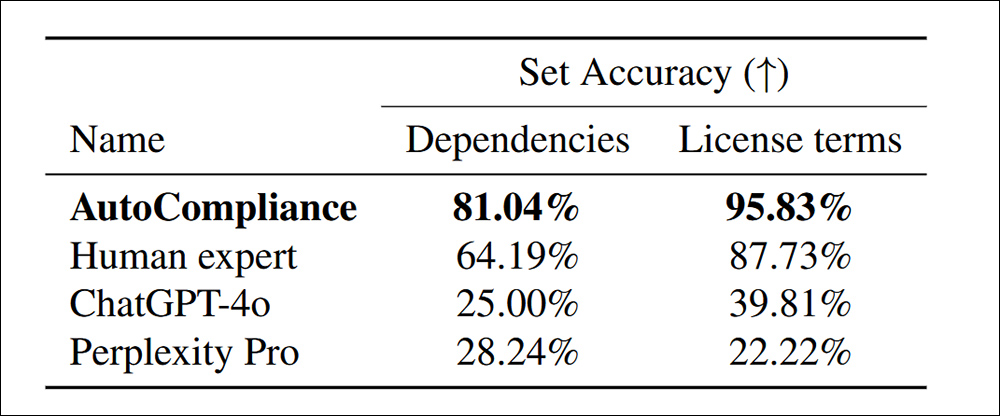
確定216個評估數據集的依賴項和許可條款的準確性。
論文指出:
“自動符號大大勝過所有其他代理商和人類專家,在每個任務中的準確度為81.04%和95.83%。相比之下,Chatgpt-4O和困惑Pro均分別顯示出源和許可任務的準確性相對較低。
“這些結果凸顯了自動符號的出色表現,證明了其在處理這兩項任務的功效,同時還表明了基於AI的模型與這些域中的人類專家之間的巨大績效差距。”
在效率方面,自動符合方法僅需53.1秒即可運行,而對同等任務的同等人類評估的2,418秒相比之下。
此外,評估運行的價格為0.29美元,而人類專家則為207美元。但是,應該指出的是,這是基於每月租用GCP A2-megagpu-16GPU節點的每月14,225美元的,這意味著這種成本效益主要與大型運營有關。
數據集調查
為了進行分析,研究人員選擇了3,612個數據集,這些數據集結合了3,000個最容易銷售的數據集,這些數據集從擁抱臉部和2023年數據出處計劃中的612個數據集中。
論文指出:
從3,612個目標實體開始,我們確定了總共17,429個獨特的實體,其中13,817個實體出現為目標實體的直接或間接依賴性。
“對於我們的經驗分析,如果實體沒有任何依賴關係和多層結構,則我們將一個實體及其許可依賴圖具有單層結構,如果它具有一個或多個依賴關係。
“在3,612個目標數據集中,有2,086(57.8%)具有多層結構,而其他1,526(42.2%)具有沒有依賴性的單層結構。”
受版權保護的數據集只能與法律權限重新分配,法律權限可能來自許可證,版權法例外或合同條款。未經授權的重新分配可能會導致法律後果,包括侵犯版權或違反合同行為。因此,必須清楚地識別違規行為至關重要。
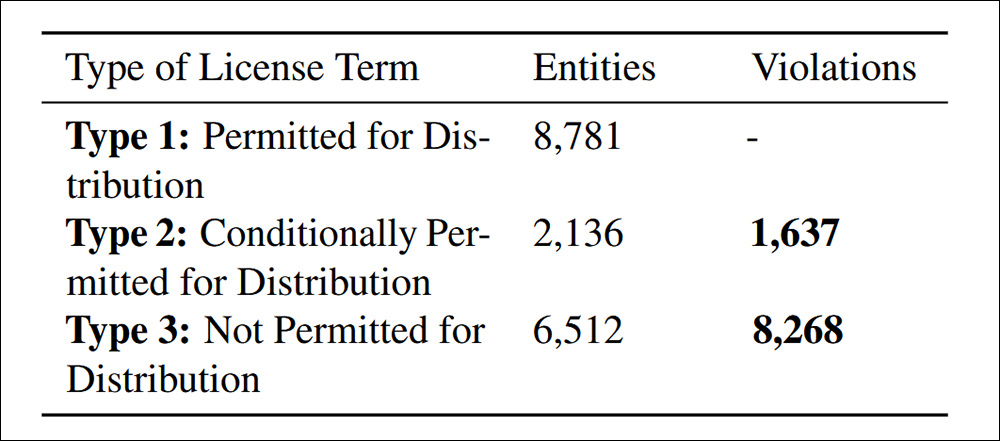
根據本文引用的標準4.4發現的分配違規行為。數據合規性。
該研究發現,有9,905例不合規數據集再分配,分為兩類:在許可條款下明確禁止了83.5%的人,這使得重新分配是明顯的違反法律違反的; 16.5%的數據集涉及具有衝突的許可條件的數據集,理論上允許重新分配,但未能滿足所需條款,從而造成了下游法律風險。
作者承認,Nexus提出的風險標準不是普遍的,並且可能因管轄權和AI應用而有所不同,並且未來的改進應著重於適應不斷變化的全球法規,同時精煉AI驅動的法律審查。
結論
這是一份ProLix且在很大程度上是不友好的論文,但解決了當前行業採用AI的最大障礙因素 – 顯然,各種實體,個人和組織顯然會要求“開放”數據的可能性。
在DMCA下,違規行為可能在法律上造成高額罰款 人均 基礎。在研究人員發現的情況下,違規行為可能陷入數百萬的地方,潛在的法律責任確實很重要。
此外,至少在美國有影響力的市場中,可以證明可以從上游數據中受益的公司(像往常一樣)無知。他們目前也沒有任何逼真的工具,可以穿透埋在據稱是開源數據集許可協議中的迷宮含義。
制定諸如Nexus之類的系統的問題是,它在美國內部的每個國家或歐盟內部的每一個基礎上都要挑戰它。創建真正的全球框架的前景(一種“數據集出處的國際刑警組織”)不僅受到了所涉及的各種政府的衝突動機的破壞,而且這些事實是,這些政府和當前法律在這方面都在不斷變化的事實。
* 我將超鏈接替換為作者的引用。
† 紙張中規定了六種類型,但最後兩種未定義。
首次出版於2025年3月7日,星期五