
ट्रांसफार्मर आर्किटेक्चर के कारण, बड़े -लैंगुएज मॉडल डेल्स (एलएलएम) काफी आगे बढ़ गए हैं, जिसने डेलो के हाल के मॉडल के साथ सैकड़ों हजारों टोकन को संसाधित करने की क्षमताओं को दिखाया, जैसे कि -PRO 1.5, क्लाउड -3, GPT4, और लालामा 3.1। हालांकि, यह विस्तारित संदर्भ लंबाई व्यावहारिक तैनाती के लिए महत्वपूर्ण चुनौतियां प्रस्तुत करती है। जैसे -जैसे अनुक्रम की लंबाई बढ़ जाती है, विलंबता बढ़ जाती है और मेमोरी बैरियर एक गंभीर बाधा बन जाता है। केवी नकद, जो अनुमान के दौरान GPU मेमोरी में जानकारी को संदर्भित करता है, संदर्भ की लंबाई के साथ आनुपातिक रूप से बढ़ता है, जिससे स्मृति संतृप्ति होती है। यह बुनियादी सीमा व्यापक इनपुट अनुक्रमों को संभालते समय कुशल हीनेंस प्रक्रियाओं में बाधा डालती है, जिससे इष्टतम ptimization समाधानों के लिए एक दबाव की आवश्यकता होती है।
जब प्रशिक्षण मुक्त तरीके मौजूद होते हैं, तो वे अक्सर कुंजी-मूल्य जोड़ी के महत्व को निर्धारित करने के लिए वजन के वजन तक पहुंच पर निर्भर करते हैं, जिससे फ्लैशटेशन जैसे कुशल ध्यान एल्गोरिदम के साथ असंगत हो जाता है। इन तरीकों को अक्सर ध्यान मैट्रिसेस की आंशिक वसूली की आवश्यकता होती है, जो समय और मेमोरी ओवरहेड दोनों का प्रतिनिधित्व करती है। नतीजतन, मौजूदा संपीड़न एल्गोरिदम मुख्य रूप से मेमोरी-लिमिटेड पे जेनरेशन प्रक्रियाओं को कम करने के बजाय उत्तर वेतन उत्पादन का भुगतान करने से पहले उत्तर देने से पहले संपीड़ित संकेतों के लिए काम करते हैं। यह मूल सीमाएं संपीड़न तकनीकों की आवश्यकता को उजागर करती हैं जो वास्तुशिल्प परिवर्तनों की आवश्यकता के बिना मॉडल प्रदर्शन को बनाए रखती हैं या स्थापित दक्षता एल्गोरिदम के साथ स्थिरता के साथ समझौता करती हैं।
सोरबो विश्वविद्यालय, इरिया फ्रांस, रोम के सेपियनज़ा विश्वविद्यालय, एडिनबर्ग विश्वविद्यालय और न्यूनतम। क्यू-फिल्टरएक मजबूत प्रशिक्षण-मुक्त केवी कैश संपीड़न तकनीक जो मॉडल प्रदर्शन का त्याग किए बिना मेमोरी की खपत के लिए Ze को Ze pttizing के लिए क्वेरी-आधारित फ़िल्टरिंग का उपयोग करती है। क्यू-फिल्टर वर्तमान क्वेरी के साथ उनकी स्थिरता के आधार पर, ध्यान के वजन के आधार पर, कुंजी-मूल्य जोड़े का मूल्यांकन करके काम करते हैं। यह दृष्टिकोण एक कुशल ध्यान एल्गोरिदम के साथ संगतता की गारंटी देता है जैसे कि FLASHION या पुनर्व्यवस्था या वास्तुशिल्प परिवर्तनों की आवश्यकता को समाप्त करते समय। केवल सबसे अधिक प्रासंगिक संदर्भ जानकारी को गतिशील रूप से मूल्यांकन और बनाए रखने से, क्यू-फिल्टर सूचकांक की गुणवत्ता को बनाए रखते हुए महत्वपूर्ण मेमोरी में कमी प्राप्त करते हैं। यह विधि एक सुव्यवस्थित संपीड़न पाइपलाइन पर लागू होती है जो मौजूदा एलएलएम परिनियोजन के साथ एकीकृत होती है, जो एक मेमोरी-ऑंट्रेंड वातावरण के लिए एक व्यावहारिक समाधान प्रदान करती है, मॉडल की क्षमता को प्रभावी ढंग से लंबे समय तक-टेंडन इनपुट को संसाधित करने की क्षमता से समझौता किए बिना।
क्वेरी-की ज्यामिति में सैद्धांतिक अंतर्दृष्टि को ध्यान में रखते हुए, क्यू-फिल्टर कैश संपीड़न के लिए एक परिष्कृत दृष्टिकोण प्रस्तुत करता है जो क्वेरी और कुंजी वेक्टर के आंतरिक ज्यामितीय गुणों को लाभान्वित करता है। यह विधि दो महत्वपूर्ण टिप्पणियों पर स्थापित की गई है: क्वेरी और प्रमुख वितरण दोनों के पक्ष में एक सामान्य सामान्य दिशा का अस्तित्व, और क्वेरी-कुंजी अनिसोट्रोपी के निर्देशन की दिशा। सख्त गणितीय सूत्रीकरण के माध्यम से, शोधकर्ताओं से पता चलता है कि इस अनिसोट्रोपिक दिशा में प्रमुख वैक्टर प्रस्तुत करना ध्यान लॉगिट्स का एक विश्वसनीय अनुमान प्रदान करता है। यह अंतर्दृष्टि एक सुव्यवस्थित संपीड़न एल्गोरिथ्म की ओर ले जाती है जिसमें शामिल हैं: (1) मॉडल नमूनाकरण द्वारा क्वेरी अभ्यावेदन एकत्र करने के लिए, (2) राइट-वेटर के लिए कम्प्यूटिंग सिंगुलर वैल्यू अपघटन (एसवीडी), और (3) प्रत्येक ध्यान के लिए एक सकारात्मक क्यू-फिल्टर प्राप्त करने के लिए। अनुमान के दौरान, विधि रणनीतिक रूप से इन फिल्टर के साथ सबसे कम प्रक्षेपण मूल्यों के साथ मुख्य-मूल्य जोड़े प्रदान करती है। समूह-क्वेरी फोकस का उपयोग करने वाले मॉडल के लिए, क्यू-फिल्टर केवल समूहीकृत क्वेरी अभ्यावेदन में औसत फिल्टर। महत्वपूर्ण रूप से, जब अव्यक्त स्थान के मूल गुणों को अवशोषित किया जाता है, तो बाकी संदर्भ-एएस-ओस्ट ओस्ट ओस्ट के साथ परिणामी क्यू-फिल्टर, मॉडल प्रशिक्षण के बाद इस दृष्टिकोण को केवल एक बार की तैयारी कदम की आवश्यकता होती है।
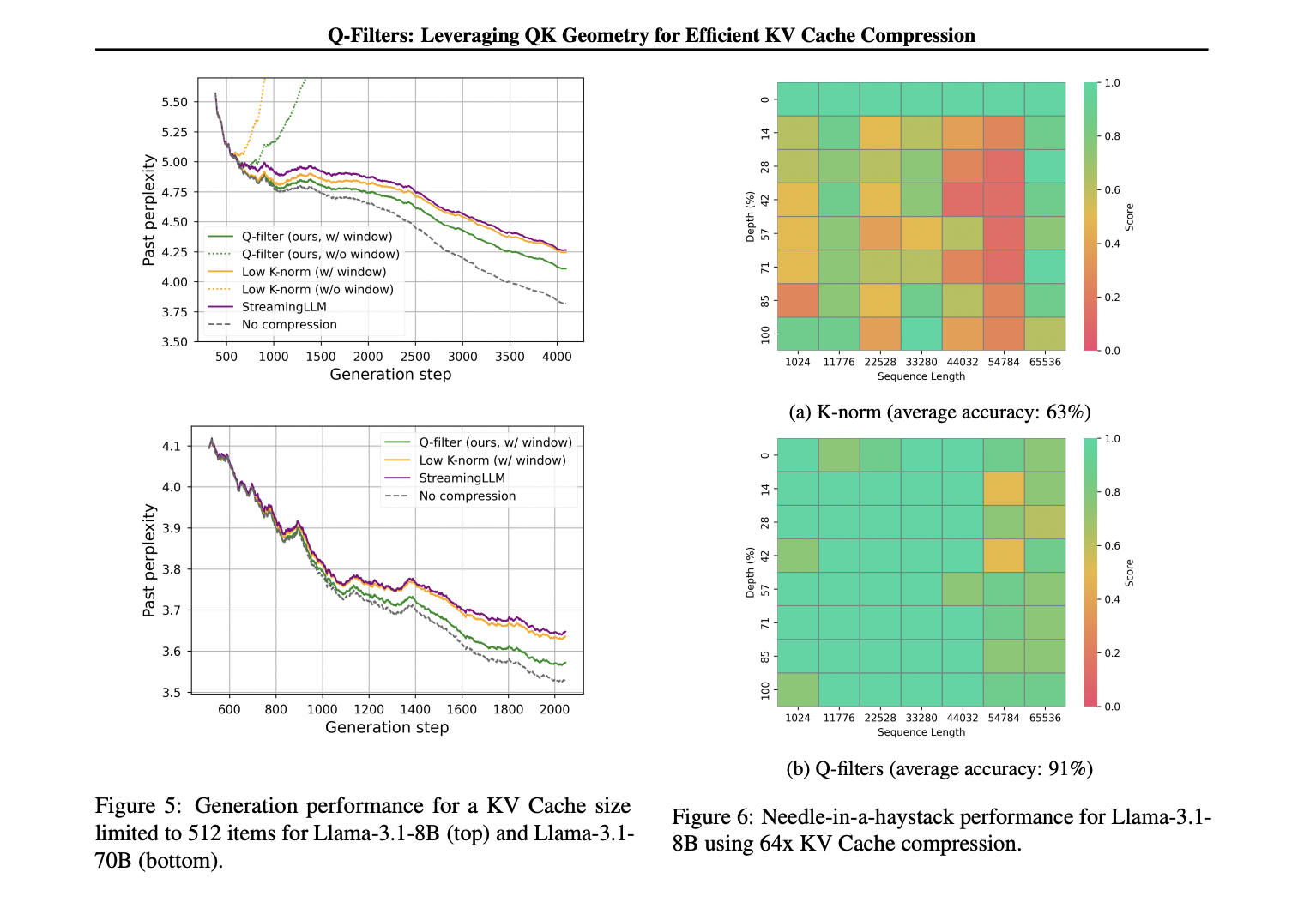
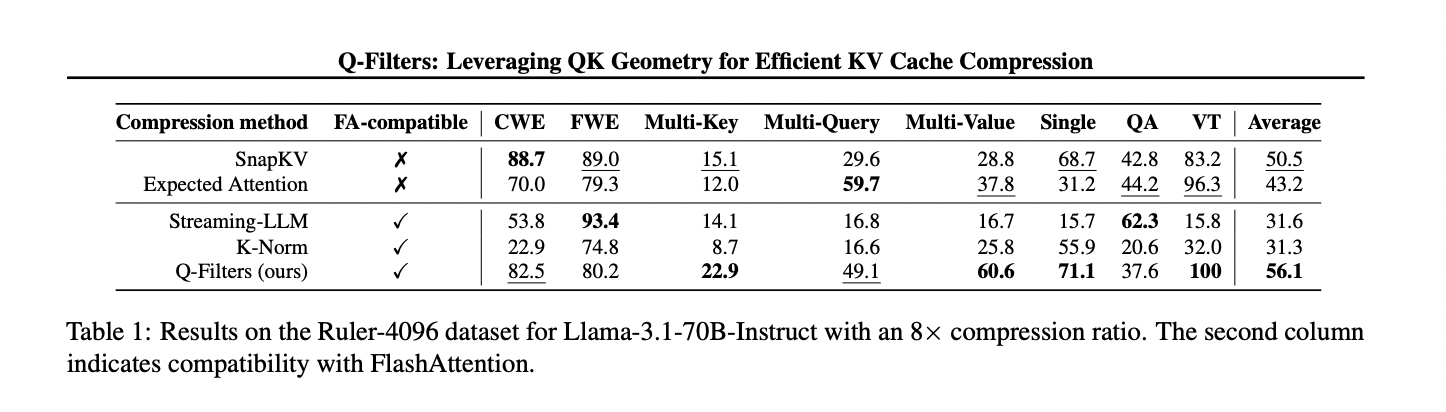
क्यू-फिल्टर कई मूल्यांकन दृश्यों में असाधारण प्रदर्शन दिखाते हैं, लगातार मौजूदा कैश संपीड़न विधियों को पूरा करते हैं। एक ढेर डेटासेट पर भाषा मॉडलिंग परीक्षणों में, तकनीक सभी संपीड़न योजनाओं में सबसे कम घबराहट प्राप्त करती है, अधिकतम कैश का आकार 512 जोड़े तक कितना है और विस्तारित अनुक्रम सीमित हैं। यह प्रदर्शन लाभ प्रभावी रूप से बड़े मॉडल स्केल देता है, जिसमें लामा -3.1-70B एक महत्वपूर्ण घबराहट में कमी दिखाता है, विशेष रूप से अनुक्रमों के बाद के हिस्सों में जहां संदर्भित अवधारण महत्वपूर्ण हो जाता है। चुनौतीपूर्ण सुई-इन-द-होस्ट एसीके काम में, क्यू-फिल्टर K- मान के% 63% की तुलना में एक प्रभावशाली 91% सटीकता बनाए रखते हैं, जो 1k से 64k टोकन तक चरम संदर्भ लंबाई में महत्वपूर्ण जानकारी को सफलतापूर्वक संरक्षित करता है। शासक डेटासेट पर व्यापक मूल्यांकन विधि की उत्कृष्टता को पहचानता है, विशेष रूप से उच्च संपीड़न दरों (32 ×) पर, जहां क्यू-फिल्टर लंबे संदर्भ मॉडलिंग बेंचमार्क में उच्चतम स्कोर प्राप्त करते हैं। इसके अलावा, प्रौद्योगिकी अंशांकन आवश्यकताओं के बारे में एक महत्वपूर्ण ताकत दिखाती है, विभिन्न अंशांकन डेटासेट में 1000 नमूनों के साथ और वास्तविक दुनिया के कार्यान्वयन के लिए इसकी व्यावहारिक दक्षता, उच्च वेक्टर स्थिरता से अधिक रिटर्न के साथ।
क्यू-फिल्टर कई मूल्यांकन दृश्यों में असाधारण प्रदर्शन दिखाते हैं, लगातार मौजूदा कैश संपीड़न विधियों को पूरा करते हैं। एक ढेर डेटासेट पर भाषा मॉडलिंग परीक्षणों में, तकनीक सभी संपीड़न योजनाओं में सबसे कम घबराहट प्राप्त करती है, अधिकतम कैश का आकार 512 जोड़े तक कितना है और विस्तारित अनुक्रम सीमित हैं। यह प्रदर्शन लाभ प्रभावी रूप से बड़े मॉडल स्केल देता है, जिसमें लामा -3.1-70B एक महत्वपूर्ण घबराहट में कमी दिखाता है, विशेष रूप से अनुक्रमों के बाद के हिस्सों में जहां संदर्भित अवधारण महत्वपूर्ण हो जाता है। चुनौतीपूर्ण सुई-इन-द-होस्ट एसीके काम में, क्यू-फिल्टर K- मान के% 63% की तुलना में एक प्रभावशाली 91% सटीकता बनाए रखते हैं, जो 1k से 64k टोकन तक चरम संदर्भ लंबाई में महत्वपूर्ण जानकारी को सफलतापूर्वक संरक्षित करता है। शासक डेटासेट पर व्यापक मूल्यांकन विधि की उत्कृष्टता को पहचानता है, विशेष रूप से उच्च संपीड़न दरों (32 ×) पर, जहां क्यू-फिल्टर लंबे संदर्भ मॉडलिंग बेंचमार्क में उच्चतम स्कोर प्राप्त करते हैं। इसके अलावा, प्रौद्योगिकी अंशांकन आवश्यकताओं के बारे में एक महत्वपूर्ण ताकत दिखाती है, विभिन्न अंशांकन डेटासेट में 1000 नमूनों के साथ और वास्तविक दुनिया के कार्यान्वयन के लिए इसकी व्यावहारिक दक्षता, उच्च वेक्टर स्थिरता से अधिक रिटर्न के साथ।
क्यू-फिल्टर एक प्रशिक्षण-मुक्त कैश संपीड़न विधि प्रस्तुत करता है जो क्वेरी वेक्टर के मुख्य एसवीडी घटक पर प्रमुख प्रतिनिधित्व करता है, ध्यान के स्कोर का सटीक अनुमान लगाता है। ध्यान के वजन पर आरोप लगाने के बिना फ्लैश आकर्षण के साथ संगत, यह कुशल दृष्टिकोण भाषा मॉडलिंग, सुई-इन-एस्टेक परीक्षणों और 70B आयामों के लिए मॉडल के लिए सत्तारूढ़ बेंचमार्क में सबसे अच्छा प्रदर्शन दिखाता है। क्यू-फिल्टर प्रासंगिक समझ क्षमताओं से समझौता किए बिना स्मृति-सीमित एलएलएम परिनियोजन के लिए प्रभावी उपाय प्रदान करते हैं।
जाँच करना गले के चेहरे पर कागज और क्यू-फिल्टर। इस शोध के लिए सभी श्रेय इस परियोजना के शोधकर्ताओं को जाते हैं। इसके अलावा, हमें फॉलो करने के लिए स्वतंत्र महसूस करें ट्विटर और हमसे जुड़ने के लिए मत भूलना 80K+ एमएल सबमिटेड।
। अनुशंसित रीडिंग- एलजी एआई रिसर्च नेक्सस प्रकाशित करता है: एक उन्नत प्रणाली एआई एजेंट एआई सिस्टम और डेटा अनुपालन मानकों को एआई डेटासेट में कानूनी चिंताओं को खत्म करने के लिए
ASJAD मार्केटकपोस्ट में एक इंटर्न कंसल्टेंट है। वह भारतीय संस्थान प्रौद्योगिकी एफ प्रौद्योगिकी, खड़गपुर में मैकेनिकल इंजीनियरिंग में बीटेक मना रहे हैं। असजाद एक मशीन लर्निंग और डीप वांडा एजुकेशन उत्साही है जो हमेशा हेल्थकेयर में मशीन लर्निंग अनुप्रयोगों पर शोध करता है।
🚨 अनुशंसित ओपन-सीरस एआई प्लेटफॉर्म: ‘इंटेलिजेंट एक ओपन सोर्स मल्टी-एजेंट फ्रेमवर्क है जो कॉम्प्लेक्स वार्तालाप एआई सिस्टम का मूल्यांकन करता है’ (ईडी)