

बड़े -स्केल सुदृढीकरण शिक्षा (आरएल) तर्क के कार्यों पर भाषा मॉडल की जटिल समस्याओं को हल करने के कौशल में महारत हासिल करने के लिए एक आशाजनक तकनीक बन गई है। वर्तमान में, Openai के O1 और दीप्सिक के R1-Zero तरीकों ने महत्वपूर्ण प्रशिक्षण समय को स्केलिंग घटनाओं को दिखाया है। बेंचमार्क प्रदर्शनी और दोनों मॉडलों की प्रतिक्रिया लंबाई संतृप्ति के संकेत के बिना प्रशिक्षण के तराजू के रूप में लगातार और लगातार बढ़ती है। इस प्रगति से प्रेरित होकर, इस पेपर के शोधकर्ताओं ने आधार मॉडल पर सीधे प्रशिक्षण द्वारा इस नए स्केलिंग इवेंट की खोज की है और इस दृष्टिकोण को तर्कसंगत-शून्य प्रशिक्षण के रूप में पहचाना है।
स्टेपफैन और त्सुइगा विश्वविद्यालय के शोधकर्ताओं ने भाषा मॉडल, ओपन-रैनसोर-जीरो (ORZ) के लिए बड़े पैमाने पर तर्कसंगत आरएल प्रशिक्षण का एक खुला स्रोत प्रस्तावित किया है। यह एक व्यापक अनुसंधान समुदाय में उन्नत आरएल प्रशिक्षण तकनीकों तक पहुंचने के लिए महत्वपूर्ण प्रगति का प्रतिनिधित्व करता है। ORZ सत्यापित पुरस्कारों के तहत विभिन्न तर्क कौशल को बढ़ाता है, जिसमें अंकगणित, तर्क, कोडिंग और सामान्य समझ के कार्य शामिल हैं। यह एक व्यापक प्रशिक्षण रणनीति के माध्यम से प्रशिक्षण स्थिरता, प्रतिक्रिया लंबाई ऑप्टिमाइज़ेशन और बेंचमार्क प्रदर्शन में सुधार के लिए महत्वपूर्ण चुनौतियों को समाप्त करता है। पिछले दृष्टिकोणों के विपरीत जो सीमित कार्यान्वयन का विवरण प्रदान करते हैं, ORZ अपनी विधि और सर्वोत्तम प्रयासों में विस्तृत अंतर्दृष्टि देता है।
ORZ फ्रेमवर्क एक बेस मॉडल के रूप में Qwen2.5- {7B, 32B} का उपयोग करता है, और प्रारंभिक ठीक-ट्यूनिंग चरणों के बिना सीधे बड़े पैमाने पर आरएल प्रशिक्षण लागू करता है। सिस्टम मानक पीपीओ एल्गोरिथ्म के स्केल-अप संस्करण का लाभ देता है, विशेष रूप से तार्किक कार्यों के लिए इष्टतम ptimized। प्रशिक्षण डेटासेट में स्टेम, गणित और विभिन्न तर्क कार्यों पर ध्यान केंद्रित करते हुए एक सावधानीपूर्वक क्यूरेटेड प्रश्न-उत्तर-उत्तर जोड़ी शामिल है। वास्तुकला में अनुमान गणना को बढ़ाने के लिए डिज़ाइन किया गया एक विशेष शीघ्र नमूना शामिल है। OpenRLHF पर कार्यान्वयन का निर्माण किया गया है, जिसमें कुशल बड़े पैमाने पर प्रशिक्षण के लिए लचीले ट्रेनर, GPU कोलोकेशन जेनरेशन और एडवांस्ड लोड फ्लड-बैक-बैक सपोर्ट मैकेनिज्म सहित महत्वपूर्ण सुधार शामिल हैं।
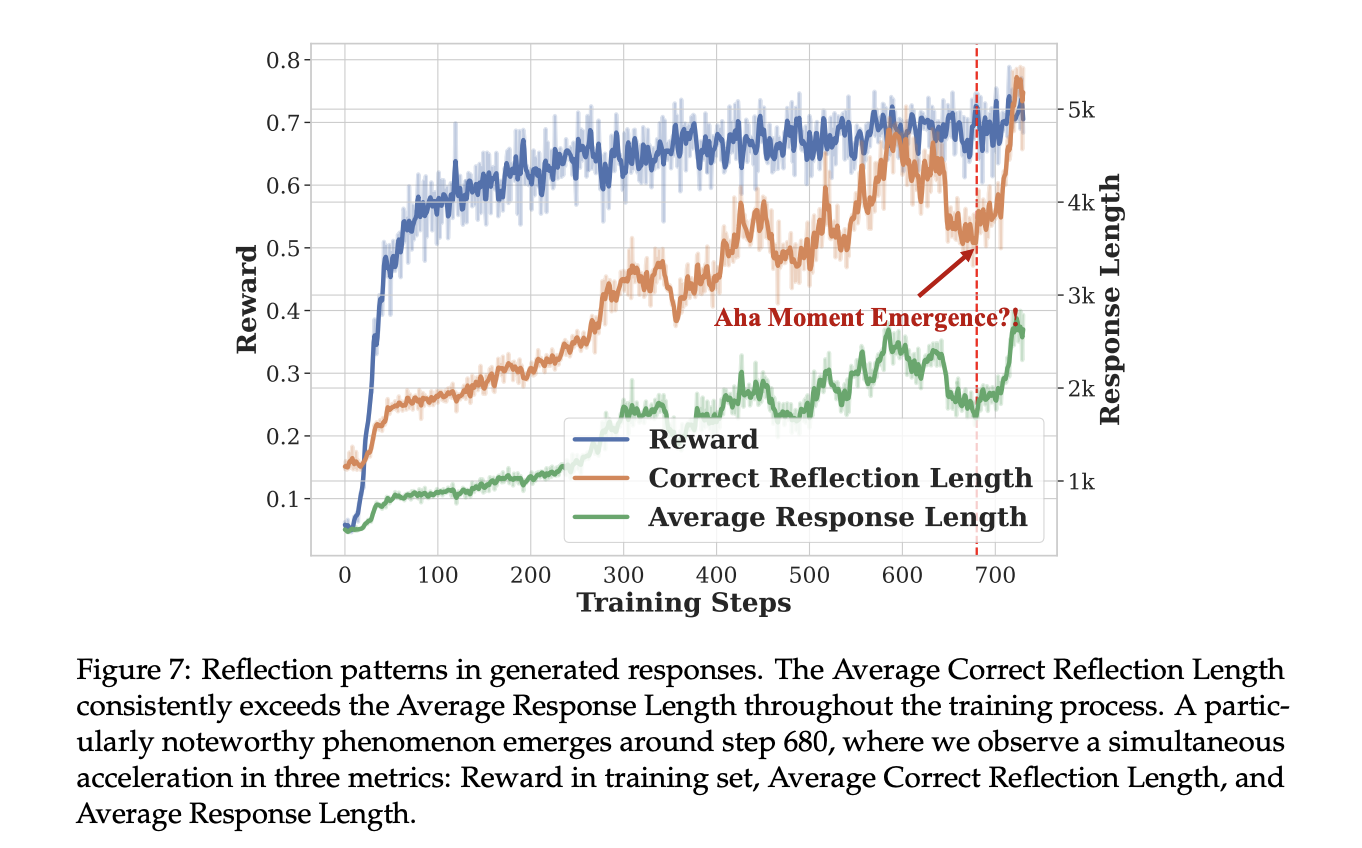
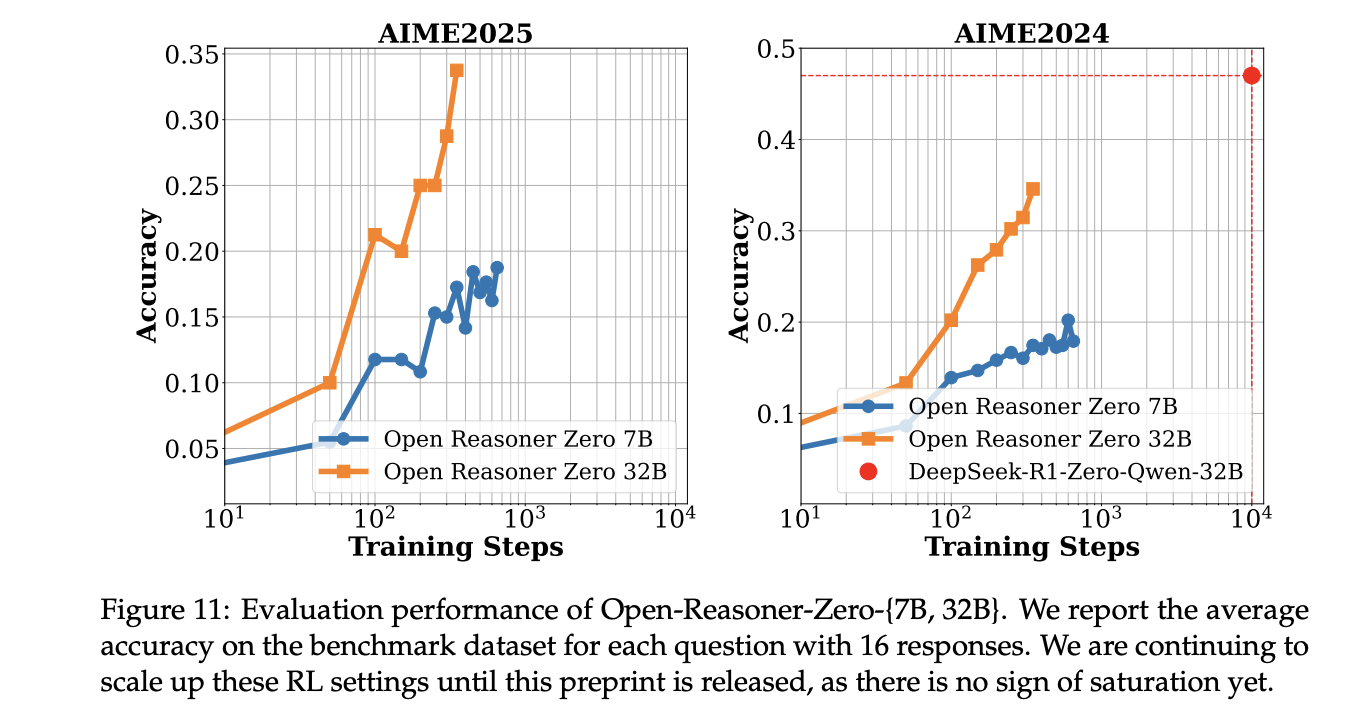
प्रशिक्षण के परिणाम ओपन-रैंज़र-जीरो 7 बी और 32 बी दोनों के लिए कई मेट्रिक्स में महत्वपूर्ण प्रभाव में सुधार दिखाते हैं। प्रशिक्षण वक्र पुरस्कार मैट्रिक्स और प्रतिक्रिया लंबाई में निरंतर वृद्धि को प्रकट करते हैं, एक महत्वपूर्ण “चरण क्षण” घटना के साथ, जो तर्क क्षमताओं में अचानक सुधार दिखाता है। प्रतिक्रिया लंबाई स्केल-अप बनाम डीप्सिक-आर 1-जीरो, ओपन-रीनज़र-शून्य -32 बी मॉडल, केवल 1/5.8 प्रशिक्षण चरणों के साथ डीपकिक-आर 1-जीरो (671 बी एमओई) की तुलनात्मक प्रतिक्रिया लंबाई प्राप्त करता है। यह दक्षता बड़े -स्केल आरएल प्रशिक्षण के लिए कम से कम दृष्टिकोण की प्रभावशीलता को मान्य करती है।
मुख्य प्रायोगिक परिणाम बताते हैं कि ओपन-रैंज़र-शून्य मल्टीपल इवैल्यूएशन मैट्रिक्स में, विशेष रूप से 32 बी कॉन्फ़िगरेशन में, असाधारण रूप से प्रदर्शन किया गया। यह एक GPQA है। DEEPSK-R1-ZERO-QUEVAN 2.5-32B की तुलना में डायमंड बेंचमार्क पर सर्वोत्तम परिणाम प्राप्त करता है, जबकि महत्वपूर्ण प्रशिक्षण दक्षता के साथ केवल 1/30 प्रशिक्षण चरणों की आवश्यकता होती है। इसके अलावा, 7B वेरिएंट निरंतर सटीकता में सुधार और नाटकीय प्रतिक्रिया पैटर्न के साथ दिलचस्प सीखने की गतिशीलता दिखाता है। मूल्यांकन के दौरान एक विशेष “चरण क्षण” घटना देखी गई है, जो कि पुरस्कार और प्रतिक्रिया लंबाई दोनों में अचानक वृद्धि की विशेषता है, विशेष रूप से GPQA हीरे और AIM 2024 बेंचमार्क में।
इस पत्र में, शोधकर्ताओं ने ओपन-रैंजर-शून्य का परिचय दिया, जो एक भाषा मॉडल के लिए बड़े पैमाने पर तर्कसंगत आरएल प्रशिक्षण लोकतंत्रीकरण में एक महत्वपूर्ण लक्ष्य का प्रतिनिधित्व करता है। अनुसंधान से पता चलता है कि GAE और नियम -आधारित इनाम कार्यों के साथ वेनिला पीपीओ का उपयोग करके एक सरल दृष्टिकोण अधिक जटिल प्रणालियों की तुलना में प्रतिस्पर्धी परिणाम प्राप्त कर सकता है। केएल नियमितीकरण के बिना सफल कार्यान्वयन साबित करता है कि मजबूत तर्क क्षमताओं को प्राप्त करने के लिए जटिल वास्तुशिल्प परिवर्तन आवश्यक नहीं हो सकते हैं। पूर्ण प्रशिक्षण पाइपलाइन को खोलकर और विस्तृत अंतर्दृष्टि साझा करके, यह कार्य स्केलिंग भाषा मॉडल तर्क क्षमताओं में भविष्य के अनुसंधान की नींव स्थापित करता है, और यह एआई विकास में एक नए स्केलिंग प्रवृत्ति की शुरुआत है।
जाँच करना पेपर और GitHB पेज। इस शोध के लिए सभी श्रेय इस परियोजना के शोधकर्ताओं को जाते हैं। इसके अलावा, हमें फॉलो करने के लिए स्वतंत्र महसूस करें ट्विटर और हमसे जुड़ने के लिए मत भूलना 80K+ एमएल सबमिटेड।
। अनुशंसित रीडिंग- एलजी एआई रिसर्च नेक्सस प्रकाशित करता है: एआई डेटासेट में कानूनी चिंताओं को खत्म करने के लिए एजेंट एआई सिस्टम और डेटा अनुपालन मानकों को एकीकृत करने वाला एक उन्नत प्रणाली

साजद अंसारी आईआईटी खड़गपुर से अंतिम वर्ष की स्नातक हैं। एक तकनीकी उत्साही के रूप में, यह एआई तकनीकों और उनके वास्तविक दुनिया के प्रभावों के प्रभाव पर ध्यान केंद्रित करके एआई के व्यावहारिक अनुप्रयोगों पर विचार करता है। इसका उद्देश्य स्पष्ट रूप से और सुलभ जटिल एआई अवधारणाओं का है।
🚨 अनुशंसित ओपन-सीरस एआई प्लेटफॉर्म: ‘इंटेलिजेंट एक ओपन सोर्स मल्टी-एजेंट फ्रेमवर्क है जो कॉम्प्लेक्स वार्तालाप एआई सिस्टम का मूल्यांकन करता है’ (ईडी)

