

चेन-वें एफए-वीआईपीएटी (सीओटी) द्वारा प्राप्त की गई प्रगति के बावजूद, बड़ी भाषा मॉडल डेलो (एलएलएमएस) को जटिल तर्क कार्यों में महत्वपूर्ण चुनौतियों का सामना करना पड़ता है। प्राथमिक चुनौती लंबी सीओटी अनुक्रमों द्वारा दर्शाई गई गणना ओवरहेड में निहित है, जो सीधे विलंबता और स्मृति आवश्यकताओं को प्रभावित करती है। एलएलएम डिकोडिंग की अयस्क टोरेंटिव प्रकृति का मतलब है कि जैसे -जैसे सीओटी अनुक्रम लंबे समय तक बढ़ते हैं, ध्यान के स्तरों में प्रसंस्करण समय और स्मृति की खपत का अनुपात होता है जहां गणना की लागत चौगुनी होती है। तर्क की सटीकता और गणना की दक्षता के बीच एक संतुलन खोजना एक महत्वपूर्ण चुनौती बन गया है, क्योंकि तर्क उपायों को कम करने के प्रयासों को अक्सर मॉडल की समस्या को हल करने की क्षमता के साथ समझौता किया जाता है।
चेन-ऑफ-थेट (COT) लॉजिक काउंट की चुनौतियों को खत्म करने के लिए विभिन्न तरीकों को विकसित किया गया है। कुछ दृष्टिकोण कुछ सोच के चरणों को सरल या अनदेखा करके तर्क प्रक्रिया को स्ट्रीमिंग करने पर ध्यान केंद्रित करते हैं, जबकि अन्य समानांतर चरण बनाने का प्रयास करते हैं। एक अलग रणनीति में लगातार संपीड़ित लॉजिक चरण शामिल हैं, जो स्पष्ट टर्म टोकन का उत्पादन किए बिना LLM को तर्क में सक्षम बनाता है। इसके अलावा, जटिल निर्देशों और लंबे संदर्भ में इनपुट को संभालने के लिए शीघ्र संपीड़न तकनीक हल्के भाषा मॉडल का उपयोग करके अधिक प्रभावी ढंग से संक्षिप्त संकेतों का उत्पादन कर रही है, काम प्रस्तुति के लिए निरंतर टोकन को नियोजित करना और उच्च-अवर टोकन के लिए फ़िल्टर करना है।
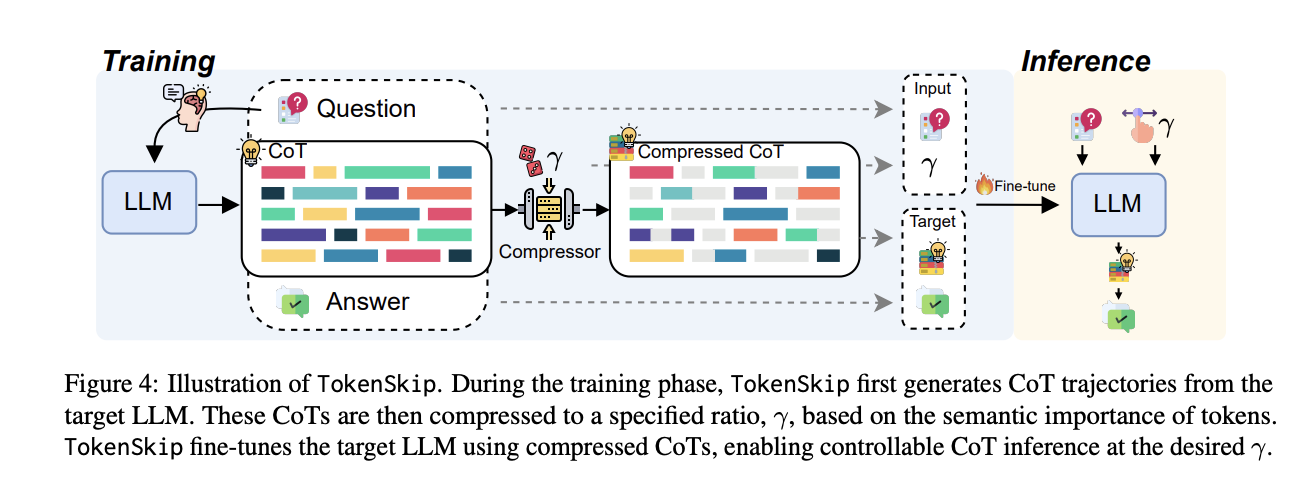
हांगकांग पॉलिटेक्निक विश्वविद्यालय और विज्ञान और प्रौद्योगिकी विश्वविद्यालय के शोधकर्ताओं ने LLMS में ZE प्रसंस्करण COT प्रसंस्करण के लिए टोकन्सकिप दृष्टिकोण का प्रस्ताव दिया है। यह मॉडल को सीओटी अनुक्रमों में कम महत्वपूर्ण टोकन छोड़ने में सक्षम बनाता है, जबकि समायोज्य संपीड़न अनुपात के साथ, जटिल तर्क टोकन के बीच संलग्नक को बनाए रखता है। सिस्टम टोकन प्रूनिंग के माध्यम से पहली संपीड़ित सीओटी प्रशिक्षण डेटा बनाकर काम करता है, इसके बाद मनाया गया ठीक-ट्यूनिंग प्रक्रिया है। बहु-मॉडल में प्रारंभिक परीक्षण, जिसमें लालामा -3.1-8B-Instruct और QWN 2.5-इंस्टॉल रेंज शामिल हैं, विशेष रूप से तर्क क्षमता को बनाए रखते हैं, जबकि कम्प्यूटेशनल ओवरहेड्स को काफी कम करते हैं।
Tokenskip की वास्तुकला मूल सिद्धांत पर बनाई गई है कि विभिन्न लॉगिन अंतिम उत्तर तक पहुंचने के लिए महत्वपूर्ण महत्वपूर्ण महत्वपूर्ण में योगदान करते हैं। इसमें दो मुख्य चरण शामिल हैं: प्रशिक्षण डेटा की तैयारी और हीन। प्रशिक्षण चरण में, सिस्टम लक्ष्य एलएलएम का उपयोग करके खाट त्रासदियों का उत्पादन करता है, और बाकी तरीके से चयनित संपीड़न अनुपात के साथ बेतरतीब ढंग से कटाई है। टोकन प्रूनिंग प्रक्रिया “महत्व स्कोरिंग” तंत्र द्वारा मार्गदर्शन करती है। अयस्क टोकन्सकिप पूर्वानुमान के दौरान एक धारदार डिकोडिंग दृष्टिकोण को बनाए रखता है, लेकिन एलएलएम को कम महत्वपूर्ण टोकन छोड़ने में सक्षम करके दक्षता बढ़ाता है। इनपुट प्रारूप का डिज़ाइन यह है कि प्रश्न और संपीड़न अनुपात अंतिम रैंक टोकन द्वारा प्रतिष्ठित हैं।
परिणाम बताते हैं कि उच्च संपीड़न दर प्राप्त करते समय बड़े भाषा मॉडल डेल्ट ऑपरेशन को बनाए रखने में अधिक निपुण होते हैं। QWEN2.5-14B-ISSTRUCTION मॉडल केवल 40% तक टोकन की खपत को कम करते हुए 0.4% डिस्प्ले ड्रॉप के साथ महत्वपूर्ण परिणाम प्राप्त करता है। Tokonskip वैकल्पिक दृष्टिकोण जैसे प्रॉम्प्ट-आधारित कमी और कटिंग की तुलना करते समय सबसे अच्छा प्रदर्शन दिखाता है। जब एक प्रॉम्प्ट-आधारित कमी लक्ष्य संपीड़न अनुपात में गिरावट और कट में महत्वपूर्ण प्रदर्शन की ओर ले जाती है, तो टोकनकिप तर्क क्षमताओं को बनाए रखते हुए एक स्पष्ट संपीड़न अनुपात बनाए रखता है। मैथ -500 डेटासेट में, यह 4% से कम प्रदर्शन ड्रॉप के साथ टोकन की खपत में 30% की कमी को प्राप्त करता है।
इस पत्र में, शोधकर्ताओं ने एक टोकनस्किप की शुरुआत की, जो टोकन महत्व के आधार पर एक नियंत्रित संपीड़न तंत्र की शुरुआत करके एलएलएम के लिए आईज़िंग आईजिंग सीओटी प्रसंस्करण में महत्वपूर्ण प्रगति का प्रतिनिधित्व करता है। विधि की सफलता तर्क की सटीकता को बनाए रखना है, जबकि चयनित जटिल टोकन का चयन करके और कम महत्वपूर्ण मुद्दों को छोड़कर गणना के ओवरहेड को काफी कम करना है। दृष्टिकोण एलएलएम के साथ प्रभावी साबित हुआ है, महत्वपूर्ण संपीड़न अनुपात के साथ न्यूनतम प्रदर्शन अध: पतन भी दिखाता है। यह शोध एलएलएम में कुशल तर्क को आगे बढ़ाने के लिए नई संभावनाओं को खोलता है, मजबूत तर्क क्षमताओं को बनाए रखते हुए गणना दक्षता में भविष्य के विकास के लिए एक नींव स्थापित करता है।
जाँच करना कागज़। इस शोध के लिए सभी श्रेय इस परियोजना के शोधकर्ताओं को जाते हैं। इसके अलावा, हमें फॉलो करने के लिए स्वतंत्र महसूस करें ट्विटर और हमसे जुड़ने के लिए मत भूलना 75 k+ ml सबमिटेड।
। अनुशंसित रीडिंग- एलजी एआई रिसर्च नेक्सस प्रकाशित करता है: एआई डेटासेट में कानूनी चिंताओं को खत्म करने के लिए एजेंट एआई सिस्टम और डेटा अनुपालन मानकों को एकीकृत करने वाला एक उन्नत प्रणाली

साजद अंसारी आईआईटी खड़गपुर से अंतिम वर्ष की स्नातक हैं। एक तकनीकी उत्साही के रूप में, यह एआई तकनीकों और उनके वास्तविक दुनिया के प्रभावों के प्रभाव पर ध्यान केंद्रित करके एआई के व्यावहारिक अनुप्रयोगों पर विचार करता है। इसका उद्देश्य स्पष्ट रूप से और सुलभ जटिल एआई अवधारणाओं का है।


