


Модели крупных языков (LLMS) используют обширные вычислительные ресурсы для обработки и создания человеческого текста. Одним из новых методов расширения возможностей рассуждений в LLMS является масштабирование времени теста, которое динамически распределяет вычислительные ресурсы во время вывода. Этот подход направлен на повышение точности ответов путем уточнения процесса рассуждения модели. Поскольку модели, такие как серия Oper, представили масштабирование времени теста, исследователи стремились понять, привели ли более длительные рассуждения к улучшению производительности или альтернативные стратегии могут привести к лучшим результатам.
Масштабирование рассуждений в моделях ИИ представляет собой серьезную проблему, особенно в тех случаях, когда расширенные цепочки мышления не обязательно переводят в лучшие результаты. Исследователи ставят под сомнение предположение, что увеличение продолжительности ответов повышает точность, которые обнаружили, что более длительные объяснения могут вводить несоответствия. Ошибки накапливаются по расширенным цепочкам рассуждений, и модели часто делают ненужные самостоятельные сведения, что приводит к снижению производительности, а не к улучшению. Если масштабирование времени теста должно быть эффективным решением, оно должно с точностью сбалансировать глубину рассуждений, обеспечивая эффективное использование вычислительных ресурсов без снижения эффективности модели.
Текущие подходы к масштабированию времени теста в основном попадают в последовательные и параллельные категории. Последовательное масштабирование расширяет цепочку мыслей (COT) во время вывода, ожидая, что более расширенные рассуждения приведут к повышению точности. Тем не менее, исследования по таким моделям, как QWQ, DeepSeek-R1 (R1) и лимузин, показывают, что расширение Cots не последовательно дают лучшие результаты. Эти модели часто используют самооценку, вводя избыточные вычисления, которые разрушают производительность. Напротив, параллельное масштабирование генерирует несколько решений одновременно и выбирает лучший, основанный на заранее определенном критерии. Сравнительный анализ показывает, что параллельное масштабирование является более эффективным в поддержании точности и эффективности.
Исследователи из Университета Фудана и лаборатории Шанхайского искусственного интеллекта представили инновационный метод, который называется «кратчайшие голосования большинства» для устранения ограничений последовательного масштабирования. Этот метод оптимизирует масштабирование времени теста, используя параллельные вычисления при учете длины решения. Основное понимание этого подхода заключается в том, что более короткие решения, как правило, являются более точными, чем более длинные, поскольку они содержат меньше ненужных самостоятельных схем. Внедряя длину решения в процесс голосования большинства, этот метод повышает производительность моделей за счет приоритетов частых и кратких ответов.
Предлагаемый метод изменяет традиционное большинство голосования, учитывая количество и продолжительность решений. Обычное голосование большинства выбирает наиболее часто встречающийся ответ среди генерируемых решений, тогда как голосование с кратким большинством присваивает более высокий приоритет ответов, которые часто появляются, но также короче. Причиной этого подхода является то, что более длинные решения имеют тенденцию вводить больше ошибок из-за чрезмерных самостоятельных счетов. Исследователи обнаружили, что QWQ, R1 и лимузин генерируют все более длительные ответы, когда побуждают уточнить свои решения, часто приводя к более низкой точке. Предлагаемый метод направлен на то, чтобы отфильтровать ненужные расширения и расставаться с приоритетом более точных ответов путем интеграции длины в качестве критерия.
Экспериментальные оценки продемонстрировали, что кратчайший метод голосования большинства значительно превосходил традиционное большинство голосования по нескольким показателям. В наборе данных AIME модели, включающие этот метод, показали повышение точности по сравнению с существующими подходами масштабирования времени теста. Например, улучшения точности наблюдались в R1-Distill-32B, который достиг 72,88% по сравнению с обычными методами. Аналогичным образом, QWQ и лимузин также демонстрировали повышенную производительность, особенно в тех случаях, когда расширенные сети рассуждений ранее привели к несоответствиям. Эти результаты показывают, что предположение о том, что более длинные решения всегда дают лучшие результаты, ошибочны. Вместо этого структурированный и эффективный подход, который приоритет краткости может привести к превосходной производительности.
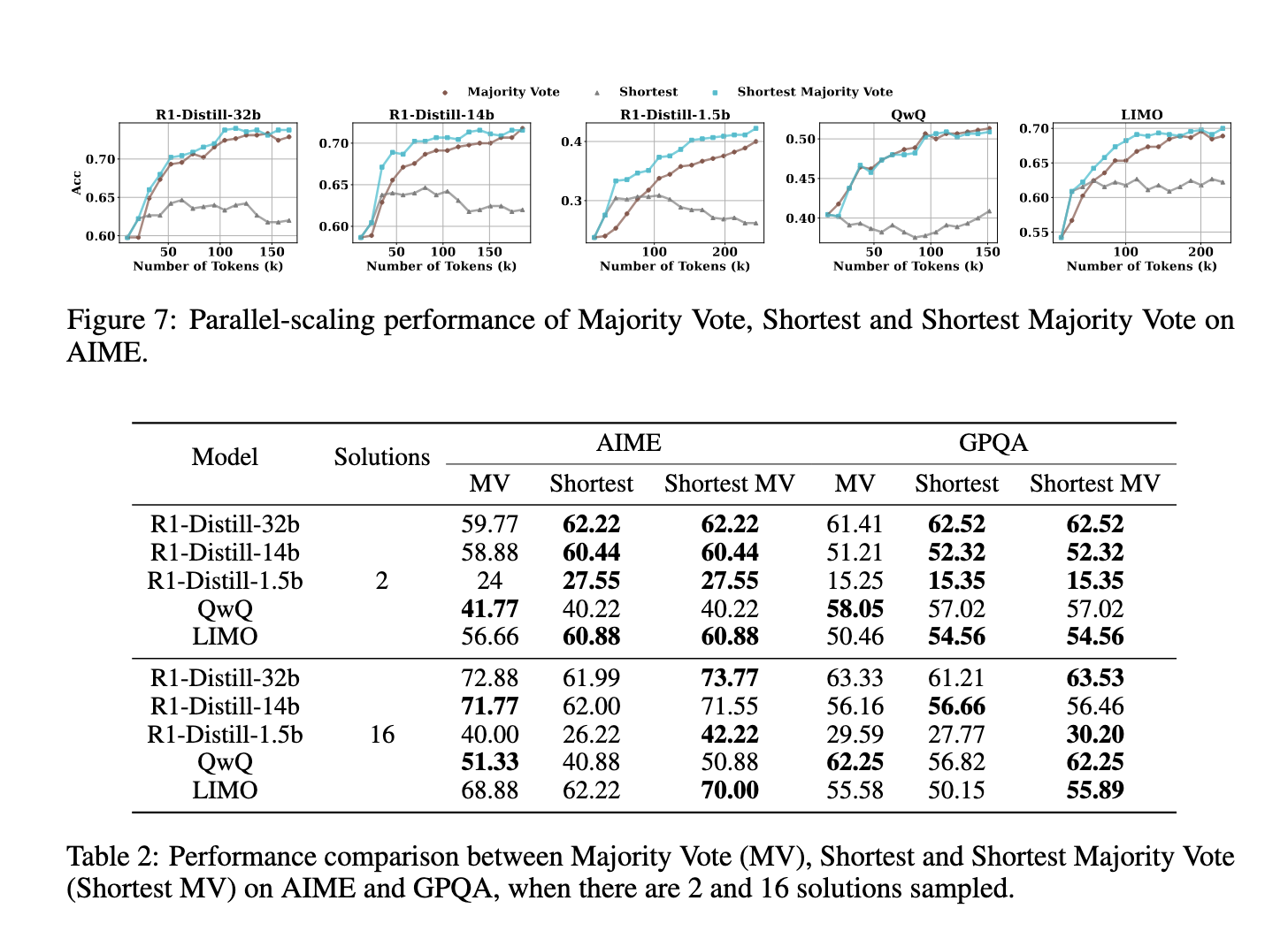
Результаты также показали, что последовательное масштабирование страдает от уменьшения доходности. В то время как первоначальные изменения могут способствовать улучшению ответов, чрезмерные изменения часто вводят ошибки, а не исправляют их. В частности, такие модели, как QWQ и R1-Distill-1.5b, имели тенденцию изменять правильные ответы на неверные, а не повышать точность. Это явление дополнительно подчеркивает ограничения последовательного масштабирования, усиливая аргумент о том, что более структурированный подход, такой как кратчайший большинство голосов, необходим для оптимизации масштабирования времени теста.
В исследовании подчеркивается необходимость переосмыслить, как масштабирование времени теста применяется в моделях крупных языков. Вместо того, чтобы предполагать, что расширение цепочек рассуждений приводит к лучшей точности, результаты демонстрируют, что приоритет кратких высококачественных решений посредством параллельного масштабирования является более эффективной стратегией. Внедрение самых коротких голосов для большинства обеспечивает практическое и эмпирически проверенное улучшение по сравнению с существующими методами, предлагая утонченный подход к оптимизации вычислительной эффективности в LLMS. Сосредоточив внимание на структурированных рассуждениях, а не на чрезмерной самоотрации, этот метод прокладывает путь для более надежного и точного принятия решений, управляемых AI.
Проверить бумага. Весь кредит на это исследование направлено на исследователей этого проекта. Кроме того, не стесняйтесь следить за нами Twitter И не забудьте присоединиться к нашему 75K+ ML SubredditПолем
🚨 Рекомендуемое чтение AI Research выпускает Nexus: расширенная система интеграции системы ИИ и стандартов соответствия данными для решения юридических проблем в наборах данных AI
Нихил – стажер консультант в Marktechpost. Он получает интегрированную двойную степень в области материалов в Индийском технологическом институте, Харагпур. Нихил является энтузиастом AI/ML, который всегда исследует приложения в таких областях, как биоматериалы и биомедицинская наука. С большим опытом в области материальной науки, он изучает новые достижения и создает возможности для внесения вклад.


