

जे लेडेज ग्राफ (केजीएस) कृत्रिम बुद्धिमत्ता कार्यक्रमों की नींव है, लेकिन अधूरा और बिखरा हुआ है, जो उनकी प्रभावशीलता को प्रभावित करता है। DBPPDIA और Wikidata जैसे विशेष रूप से KGs में आवश्यक इकाई संबंधों की कमी होती है, जिससे पुनर्स्थापना-ऑफ-पेय-पे-जनरेशन (RAG) और अन्य मशीन-लर्निंग फ़ंक्शन में उनकी उपयोगिता को कम किया जाता है। परंपरागत निष्कर्षण विधियां अनुपस्थित महत्वपूर्ण कनेक्शन या शोर, व्यर्थ अभ्यावेदन के साथ एक छींटेदार ग्राफ प्रदान करती हैं। इसलिए, असंरचित पाठ से उच्च गुणवत्ता वाले संरचनात्मक Junowledge प्राप्त करना मुश्किल है। आर्टिफिशियल इंटेलिजेंस की मदद से, इन चुनौतियों का सामना करना महत्वपूर्ण है ताकि पुनर्निर्मित की खरीद, तर्क और अंतर्दृष्टि को सक्षम किया जा सके।
कच्चे पाठ से किलो -किलो रेक्टिक के लिए राज्य -of -art तरीके खुले सूचना निष्कर्षण और ग्राफ्रैग हैं। खुला, एक निर्भरता पार्सिंग तकनीक, संरचित (विषय, संबंध, वस्तु बर्गर) बनाती है, लेकिन बहुत जटिल और निरर्थक ट्यूमर पैदा करती है, जो स्थिरता को कम करती है। Graphrag, जो ग्राफ-आधारित Redeie खरीद और भाषा मॉडल डेलो को जोड़ती है, यह लिंकिंग में इकाई को बढ़ाता है, लेकिन Ga ense कनेक्टेड ग्राफ़ का उत्पादन नहीं करता है, जो डाउनस्ट्रीम लॉजिक प्रक्रियाओं को प्रतिबंधित करता है। दोनों तकनीकें कम इकाई संकल्प स्थिरता से घिरी हुई हैं, कनेक्टिविटी और खराब सामान्यीकरण में विभाजित हैं, जिससे वे उच्च गुणवत्ता वाले किलोस निष्कर्षण के लिए अप्रभावी हैं।
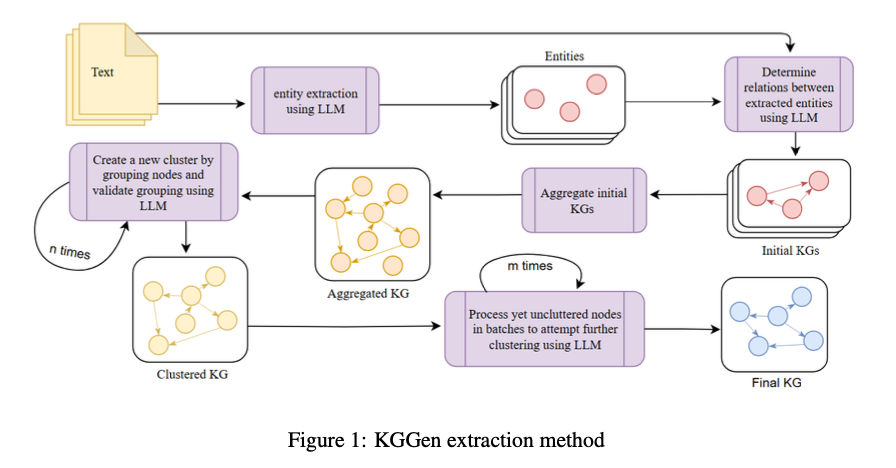
स्टैनफोर्ड विश्वविद्यालय, टोरंटो विश्वविद्यालय और सुदूर एआई के शोधकर्ताओं ने सादे पाठ से संरचित जीनवेल्ड की भाषा की भाषा की भाषा से लाभान्वित होने के लिए एक उपन्यास पाठ-से-किलो जनरेटर कैगन की शुरुआत की है। पिछले तरीकों के विपरीत, Caggen एक दोहरावदार LM- आधारित क्लस्टरिंग विधि का परिचय देता है जो पर्यायवाची निकायों और समूहन संबंधों को विलय करके racted ग्राफ को बढ़ाता है। यह बिखरे हुए और निरर्थकता को बढ़ाता है, अधिक सुसंगत और अच्छी तरह से -कनेक्टेड किलो की पेशकश करता है। KGGEN भी खदान (नोड्स का माप और किनारे में जानकारी) प्रस्तुत करता है, पाठ-से-किलो निष्कर्षण प्रदर्शन के लिए पहला बेंचमार्क निष्कर्षण विधियों के प्रमाणित माप को सक्षम करता है।
KGGEN संबंध निष्कर्षण, समेकन और इकाई और एज क्लस्टरिंग के लिए मॉड्यूल के साथ इकाई और मॉड्यूल के माध्यम से काम करता है। इकाई और संबंध निष्कर्षण के लिए मॉड्यूल, अनस्ट्रक्चर्ड टेक्स्ट से संरचित ट्रिपल (विषय, भविष्यवाणियों, ऑब्जेक्ट बोझ) को प्राप्त करने के लिए GPT-4O को नियुक्त करता है। समेकन मॉड्यूल विभिन्न स्रोतों से एक संयुक्त जीनोलेज ग्राफ (किग्रा) में एक रेक्टेंट में ट्रिपल को जोड़ता है, इसलिए संस्थाओं की एक समान प्रस्तुति सुनिश्चित करता है। इकाई और एज क्लस्टरिंग के लिए मॉड्यूल शब्दांश संस्थाओं को बढ़ाने के लिए एक दोहरावदार क्लस्टरिंग एल्गोरिथ्म का उपयोग करता है, क्लस्टर और ग्राफ कनेक्टिविटी के एक ही किनारे। DSSPY का उपयोग करके भाषा मॉडल पर एक सख्त बाधा के कार्यान्वयन से, KGGEN संरचित और उच्च लागत निष्कर्षण के अधिग्रहण को सक्षम करता है। आउटपुट को अपने जीए नॉलेज ग्राफ, इसकी जीए एनएसई कनेक्टिविटी, सिमेंटिक संगति और आर्टिफिशियल इंटेलिजेंस उद्देश्यों के लिए ऑप्टिमाइज़ेशन द्वारा प्रतिष्ठित किया जाता है।
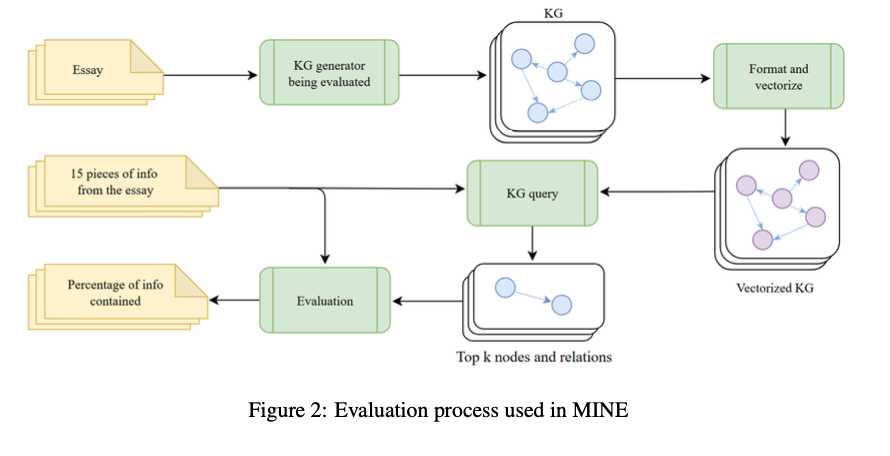
बेंचमार्किंग परिणाम पाठ स्रोतों के ract के संरचनात्मक Junowledge की सफलता का संकेत देते हैं। KGGEN को 66.5%की सटीक दर मिलती है, जो कि ग्राफ्रैग है। 47.80%और ओपीई 29.84%से खुले की तुलना में काफी अधिक है। सिस्टम अतिरेक और कनेक्टिविटी और स्थिरता Junowlede की क्षमता को सरल बनाती है और बाहर निकलने और व्रत और संरचना। तुलनात्मक विश्लेषण मौजूदा तरीकों पर निष्कर्षण वफादारी में 18% सुधार की पुष्टि करता है, एक अच्छी तरह से -स्ट्रक्टेड Junoweltge का उत्पादन करने की अपनी क्षमता को उजागर करता है। परीक्षण यह भी बताते हैं कि उत्पादित ग्राफ नर्तक और अधिक जानकारीपूर्ण है, जो उन्हें JNWLEGE राइटिव एडिविस टीयूके और एआई-आधारित लॉजिक के संदर्भ में विशेष रूप से उपयुक्त बनाता है।
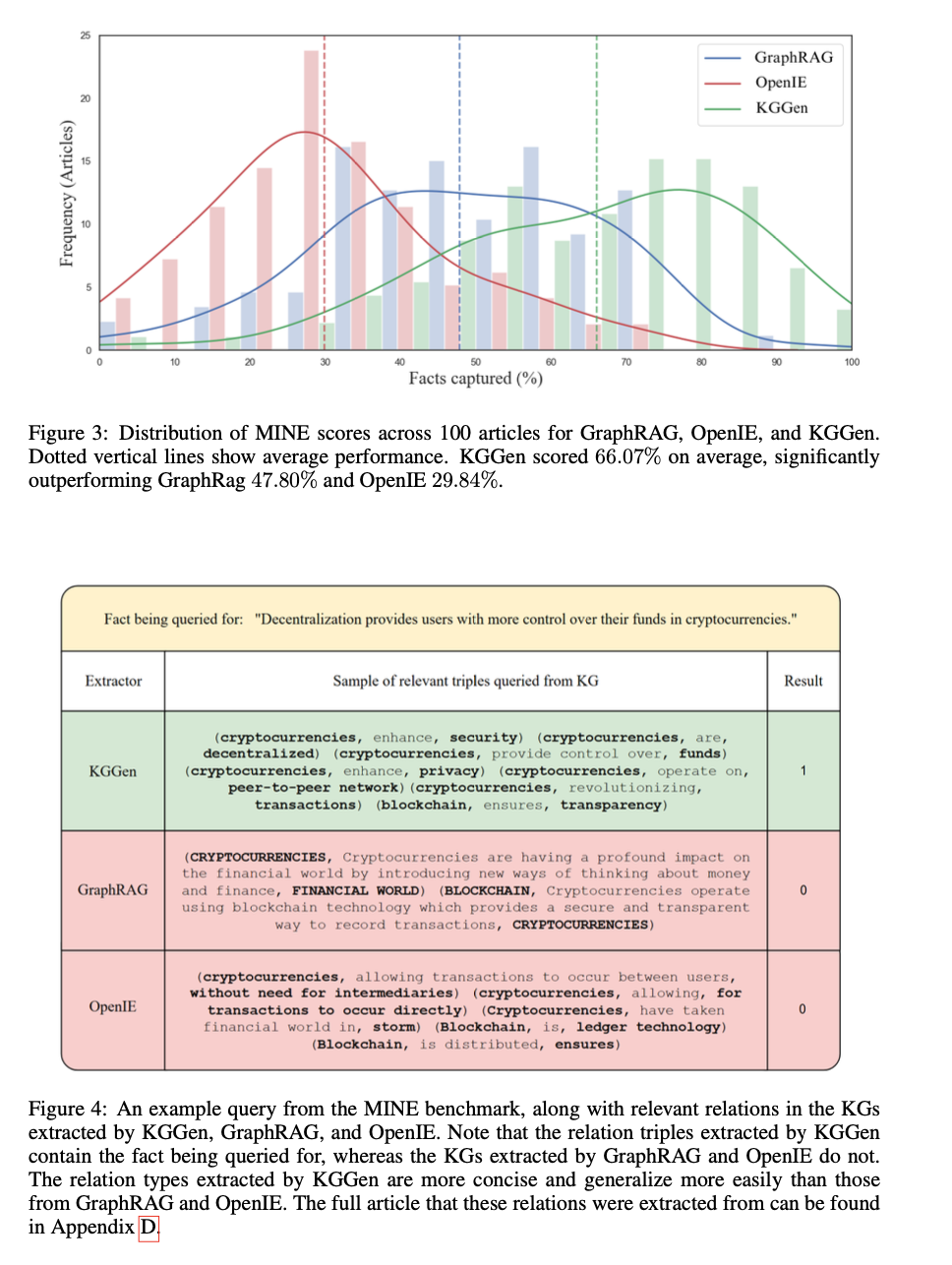
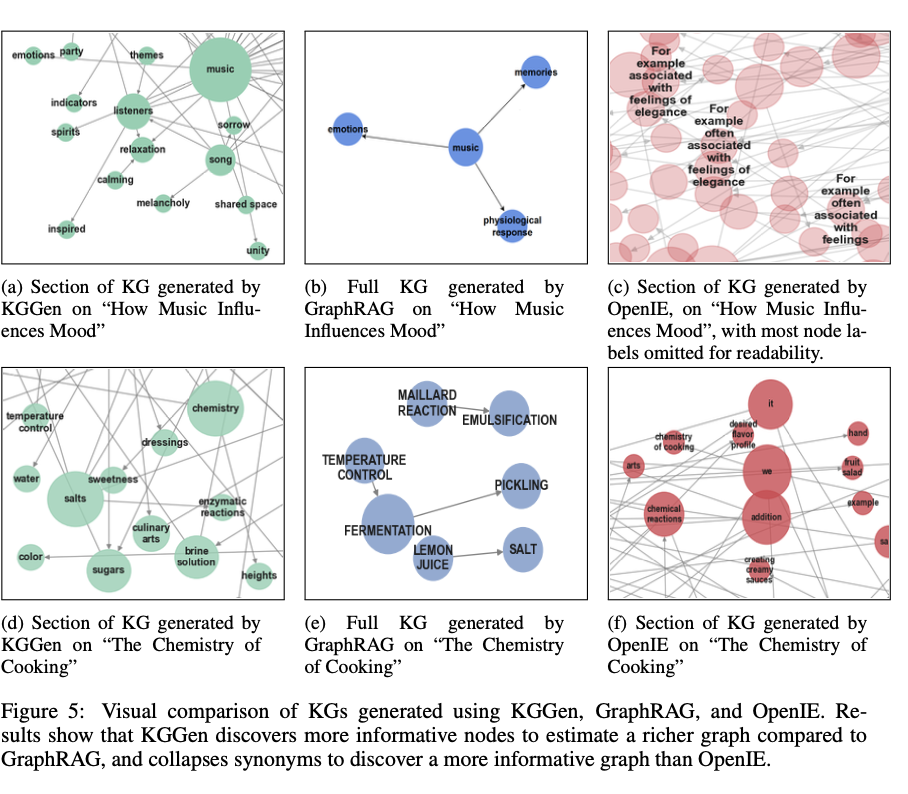
KGGEN J नॉलेज ग्राफ निष्कर्षण के क्षेत्र में एक प्रगति है क्योंकि यह उच्च गुणवत्ता वाले संरचित डेटा बनाने के लिए बार-बार क्लस्टरिंग तकनीकों के साथ भाषा मॉडल-आधारित इकाई सत्यापन को जोड़ती है। खदान बेंचमार्क पर एक कट्टरपंथी बेहतर परिशुद्धता प्राप्त करके, यह असंगठित पाठ को प्रभावी अभ्यावेदन में बदलने के लिए बार को बढ़ाता है। इस प्रगति में आर्टिफिशियल इंटेलिजेंस -बेस्ड ग्नोवलेज -आधारित ग्नोवलेज -बेड रिकवरी, लॉजिक ऑपरेशन और एम्बेडिंग आधारित शिक्षा के लिए दूरस्थ सुझाव हैं, इस प्रकार बड़े और व्यापक Junowloadge ग्राफ़ के आगे के विकास का मार्ग प्रशस्त करते हैं। भविष्य का विकास क्लस्टरिंग तकनीकों को शुद्ध करने और बड़े डेटासेट को कवर करने के लिए बेंचमार्क परीक्षणों के विस्तार पर ध्यान केंद्रित करेगा।
जाँच करना कागज़। इस शोध के लिए सभी श्रेय इस परियोजना के शोधकर्ताओं को जाते हैं। इसके अलावा, हमें फॉलो करने के लिए स्वतंत्र महसूस करें ट्विटर और हमसे जुड़ने के लिए मत भूलना 75 k+ ml सबमिटेड।
। अनुशंसित रीडिंग- एलजी एआई रिसर्च नेक्सस प्रकाशित करता है: एक उन्नत प्रणाली एआई एजेंट एआई सिस्टम और डेटा अनुपालन मानकों को एआई डेटासेट में कानूनी चिंताओं को खत्म करने के लिए
Aswin AK MaviyechPost में एक परामर्श इंटर्न है। उन्हें खड़गपुर में भारतीय प्रौद्योगिकी में दोहरी डिग्री मिल रही है। यह डेटा अभिव्यक्तियों और पंखों और मशीन लर्निंग के बारे में उत्साही है, एक मजबूत शैक्षणिक पृष्ठभूमि और वास्तविक जीवन क्रॉस-डॉमन चुनौतियों को हल करने में अनुभव लाता है।



