


大型語言模型(LLMS)通過基於輸入數據預測下一個令牌來運行,但它們的性能表明它們處理信息超出了單純的級別預測。這就提出了有關LLM在產生完整響應之前是否參與隱式計劃的問題。了解這種現象可以導致更透明的AI系統,提高效率並使產出產生更具可預測性。
與LLMS合作的一個挑戰是預測它們將如何構建響應。這些模型依次生成文本,從而控制整體響應長度,推理深度和事實準確性挑戰。缺乏明確的計劃機制意味著,儘管LLM會產生類似人類的反應,但它們的內部決策仍然不透明。結果,用戶通常依靠及時的工程來指導輸出,但是該方法缺乏精確度,並且無法洞悉該模型的固有響應公式。
現有的提煉LLM輸出的技術包括加強學習,微調和結構化提示。研究人員還嘗試了決策樹和基於外部邏輯的框架以施加結構。但是,這些方法無法完全捕獲LLMS內部處理信息。
上海人工智能實驗室研究團隊通過分析隱藏的表示以發現潛在的反應規劃行為,引入了一種新穎的方法。他們的發現表明,LLMS甚至在生成第一個令牌之前編碼其響應的關鍵屬性。研究小組檢查了他們的隱藏表示形式,並研究了LLMS是否參與緊急響應計劃。他們引入了簡單的探測模型,該模型在及時嵌入式上訓練,以預測即將到來的響應屬性。該研究將響應計劃分為三個主要領域:結構屬性,例如響應長度和推理步驟,內容屬性,包括故事編寫任務中的角色選擇以及行為屬性,例如對多項選擇答案的信心。通過分析隱藏層中的模式,研究人員發現,這些計劃能力的規模具有模型大小並在整個生成過程中發展。
為了量化響應計劃,研究人員進行了一系列探測實驗。他們訓練了模型,以使用在輸出生成之前提取的隱藏狀態表示來預測響應屬性。實驗表明,探針可以準確預測即將到來的文本特徵。研究結果表明,LLMS在其及時表示中編碼響應屬性,計劃能力在響應的開始和結束時達到頂峰。該研究進一步表明,不同規模的模型具有相似的計劃行為,較大的模型表現出更明顯的預測能力。
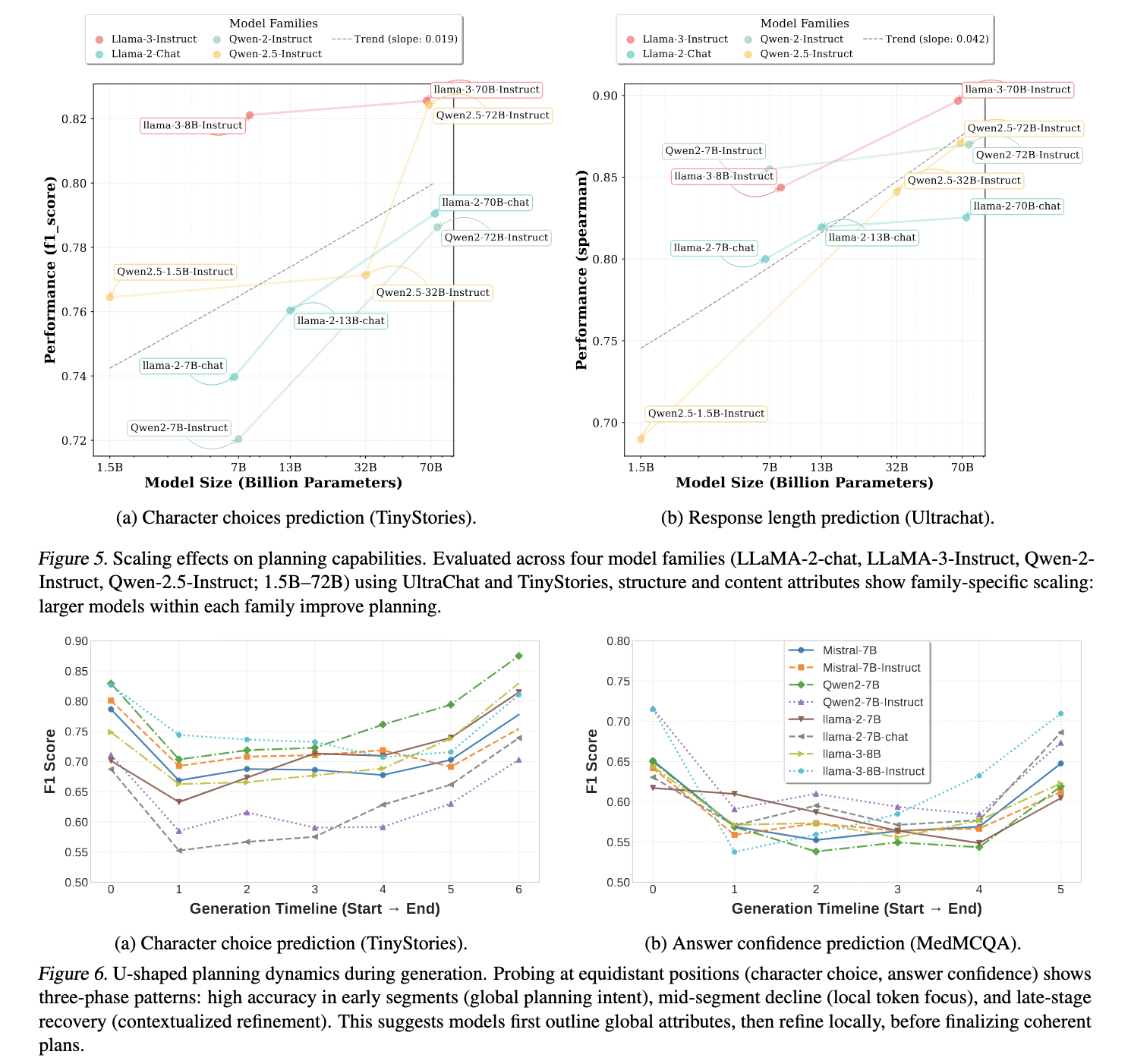
實驗揭示了基本模型和微調模型之間的計劃能力的實質性差異。微調模型在結構和行為屬性上表現出更好的預測準確性,證實了通過優化加強計劃行為的精度。例如,響應長度預測顯示了模型之間的高相關係數,在某些情況下,Spearman的相關性達到0.84。同樣,推理步驟預測與地面真實值表現出很強的一致性。諸如故事寫作中的角色選擇和多項選擇答案選擇之類的分類任務在隨機基準的上方表現出色,進一步支持LLMS內部編碼響應計劃元素的觀念。
較大的模型表現出所有屬性的卓越計劃能力。在駱駝和QWEN模型家族中,隨著參數計數的增加,計劃準確性一致地提高。研究發現,Llama-3-70B和Qwen2.5-72B-Instruct表現出最高的預測性能,而QWEN2.5-1.5B(例如QWEN2.5-1.5B)較小的模型卻難以有效編碼長期響應結構。此外,通過層的探測實驗表明,在中層中,結構屬性顯著出現,而內容屬性在後來的層中變得更加明顯。行為屬性(例如答案信心和事實一致性)在不同模型深度之間保持相對穩定。
這些發現突出了LLM行為的基本方面:它們不僅可以預測下一步的標記,而且可以在生成文本之前計劃其響應的更廣泛屬性。這種緊急的響應計劃能力對改善模型透明度和控制具有影響。了解這些內部過程可以幫助完善AI模型,從而可以更好地可預測性並減少對後期校正的依賴。未來的研究可能會探索LLM體系結構中的明確規劃模塊的整合,以增強響應連貫性和用戶指導的自定義。
查看 紙。 這項研究的所有信用都歸功於該項目的研究人員。另外,請隨時關注我們 嘰嘰喳喳 而且不要忘記加入我們的 75K+ ml子雷迪特。
🚨 推薦的閱讀-LG AI研究釋放Nexus:一個高級系統集成代理AI系統和數據合規性標準,以解決AI數據集中的法律問題
Nikhil是Marktechpost的實習顧問。他正在哈拉格布爾印度技術學院攻讀材料的綜合材料綜合學位。 Nikhil是AI/ML愛好者,他一直在研究生物材料和生物醫學科學等領域的應用。他在材料科學方面具有強大的背景,他正在探索新的進步並創造了貢獻的機會。


