


深度神經網絡看似異常的概括行為,良性過度擬合,雙重下降和成功的過度參數既不是神經網絡獨有的,也不是固有的神秘。這些現象可以通過諸如pac-bayes和可數假設界的既定框架來理解。紐約大學禮物的研究員 “軟感應偏見” 作為解釋這些現象的關鍵統一原則:而不是限制假設空間,而是具有靈活性,同時保持了對與數據一致的簡單解決方案的偏愛。該原則適用於各種模型類別,表明深度學習與其他方法沒有根本不同。但是,深度學習在特定方面仍然很獨特。
傳統上,歸納性偏見是限制偏見,從而限制了假設空間以改善概括,從而使數據消除了不適當的解決方案。卷積神經網絡通過通過參數刪除和共享對MLP施加硬性約束和翻譯等效性來體現這種方法。軟感應偏見代表了更廣泛的原理,其中優選某些解決方案而不消除同樣適合數據的替代方案。與限制性限制不同,軟偏置指南而不是限制假設空間。這些偏見通過正則化和貝葉斯先驗等機制影響訓練過程。
擁抱靈活的假設空間具有復雜的現實世界數據結構,但需要先前偏向某些解決方案才能確保良好的概括。儘管涉及過度擬合和諸如Rademacher複雜性之類的指標的傳統智慧,但像過度參數化之類的現象與對概括的直覺理解相吻合。這些現象可以通過長期建立的框架來表徵,包括Pac-Bayes和可數假設的界限。有效維度的概念為理解行為提供了額外的直覺。塑造了塑造常規概括智慧的框架通常無法解釋這些現象,從而突出了已建立的替代方法的價值來理解現代機器學習的概括屬性。
良性過度擬合描述了模型完全適合噪聲的能力,同時仍然對結構化數據概括,表明過度擬合的能力並不一定會導致對有意義問題的概括。卷積神經網絡可以符合隨機圖像標籤,同時在結構化圖像識別任務上保持較強的性能。這種行為與建立的概括框架(如VC維度和Rademacher複雜性)相矛盾,作者聲稱沒有現有的正式措施可以解釋這些模型的簡單性,儘管它們的規模很大。良性過度擬合的另一個定義被描述為“深度學習發現的關鍵奧秘之一”。但是,這並不是神經網絡獨有的,因為它可以在各種模型類別中復制。
雙重下降是指減少,增加,然後隨著模型參數增加而再次減少的概括誤差。初始模式遵循“經典制度”,其中模型捕獲了有用的結構,但最終過度合適。第二個下降發生在訓練損失接近零之後的“現代插值制度”中。為RESNET-18和線性模型顯示了雙重下降。對於重新連接,隨著每一層寬度的增加,CIFAR-100上可以看到跨凝性損失。隨著線性模型的重置或參數的層寬度增加,兩者都遵循類似的模式:有效維度上升到達到插值閾值,然後隨著概括的提高而減小。可以使用Pac-Bayes邊界正式跟踪此現象。
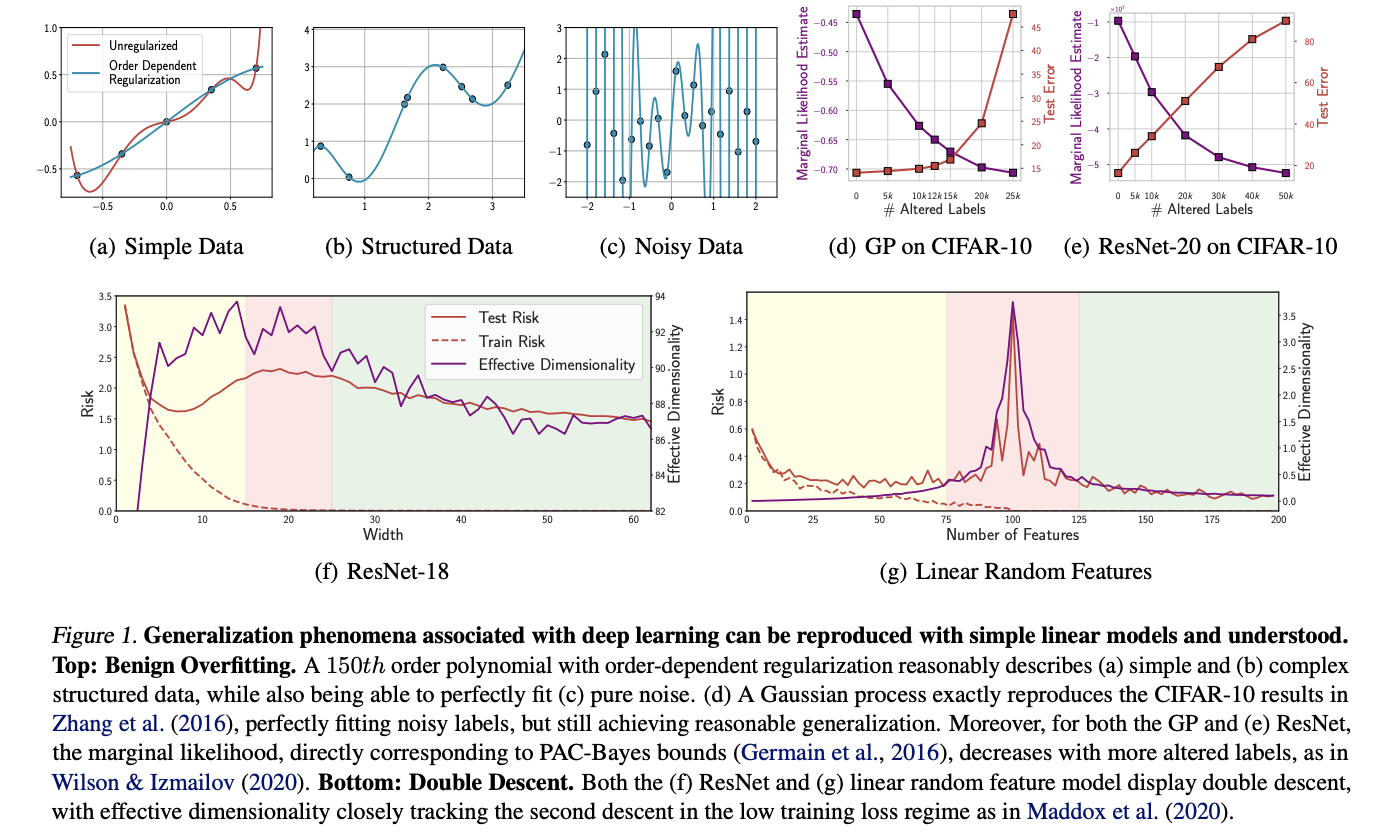
總之,過度參數化,良性過度擬合和雙重下降代表了值得繼續研究的有趣現象。但是,與普遍的信念相反,這些行為與已建立的概括框架相一致,可以在非神經模型中復制,並且可以直觀地理解。這種理解應該彌合各種研究社區,防止有價值的觀點和框架被忽視。其他現象(如Grokking和縮放定律)並未作為重新思考概括框架或神經網絡特異性的證據。最近的研究證實,這些現象適用於線性模型。此外,Pac-bayes和可數假設的界限與大語言模型保持一致。
查看 紙。 這項研究的所有信用都歸該項目的研究人員。另外,請隨時關注我們 嘰嘰喳喳 而且不要忘記加入我們的 80k+ ml子列數。
🚨 Meet Parlant:LLM優先的對話AI框架,旨在為開發人員提供對AI客戶服務代理商所需的控制和精確度,並利用行為指南和運行時監督。 🔧🎛️它是使用Python和TypeScript📦中易於使用的CLI📟和本機客戶sdks操作的。

Sajjad Ansari是來自IIT Kharagpur的最後一年的本科生。作為技術愛好者,他深入研究了AI的實際應用,重點是理解AI技術及其現實世界的影響。他旨在以清晰易於的方式表達複雜的AI概念。
PARLANT:使用LLMS💬💬(晉升)建立可靠的AI AI客戶面對面的代理商

