

मनुष्यों को भौतिकी की एक जन्मजात समझ है, जो स्थिति, आकार या रंग में अचानक परिवर्तन के बिना अनुमानित व्यवहार करने की उम्मीद करता है। यह मूल बुद्धि शिशुओं, प्राइमेट्स, बर्ड्स और समुद्री स्तनधारियों में पाई जाती है, जो मुख्य ग्नोवेलेज की परिकल्पना का समर्थन करती हैं, यह सुझाव देते हैं कि विकसित सिस्टम मनुष्यों, वस्तुओं, गुंजाइश और एजेंटों के बारे में तर्क के लिए विकसित किए गए हैं। जब AI कॉम्प्लेक्स और गणित जैसे जटिल कार्यों में मनुष्यों को पार कर लेता है, तो यह सहज भौतिक विज्ञान के साथ संघर्ष करता है, जो मोरवेक के संघर्ष को उजागर करता है। AI भौतिक तर्क के लिए दृष्टिकोण दो श्रेणियों में आता है: संरचित मॉडल, जो पूर्व निर्धारित नियमों का उपयोग करके ऑब्जेक्ट beject इंटरैक्शन की नकल करते हैं, और पिक्सेल-आधारित उत्पन्न करने वाले मॉडल, जो स्पष्ट सार के बिना भविष्य के संवेदी इनपुट की भविष्यवाणी करते हैं।
मेटा, यूनीव गुस्ताव एफिल और ईश फेयर के शोधकर्ता, सामान्य -गहरे वांडा न्यूरल नेटवर्क का पता लगाते हैं कि वे प्राकृतिक वीडियो में नकाबपोश क्षेत्रों की भविष्यवाणी करके सहज ज्ञान युक्त भौतिकी की समझ कैसे विकसित करते हैं। एक उल्लंघन-प्रतिस्पर्धी संरचना का उपयोग करते हुए, वे दिखाते हैं कि एक अमूर्त प्रस्तुति स्थान में परिणामों की भविष्यवाणी करने के लिए प्रशिक्षित मॉडल, या संयुक्त एम्बेडिंग पूर्वानुमान (JPAs)-वस्तु-वस्तु भौतिक गुणों जैसे स्थिरता और आकार स्थिरता की सटीक रूप से पहचान कर सकती है। इसके विपरीत, वीडियो पूर्वानुमान मॉडल पिक्सेल स्पेस और मल्टीमॉडल बड़े भाषा मॉडल में काम कर रहे हैं जो यादृच्छिक अनुमान के करीब प्रदर्शित होते हैं। इससे पता चलता है कि पूर्वनिर्धारित नियमों पर भरोसा करने के बजाय, एक अमूर्त स्थान में सीखना, भौतिकी की सहज समझ हासिल करने के लिए पर्याप्त है।
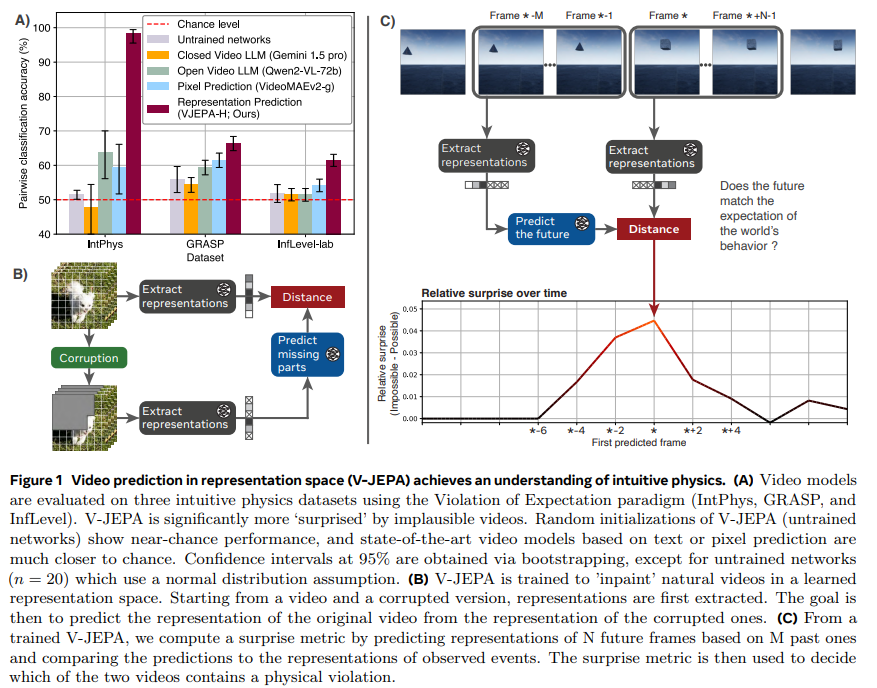
यह अध्ययन वीडियो-आधारित जेपी मॉडल, वी-जापा पर केंद्रित है, जो कि न्यूरोसाइंस में भविष्यवाणी कोडिंग सिद्धांत के साथ गठबंधन किया गया है, विद्वान प्रतिनिधित्व स्थान में भविष्य के वीडियो फ्रेम की भविष्यवाणी करता है। V-JAPA ने अन्य मॉडलों का विस्तार करते हुए इंटरफ़ेस बेंचमार्क पर इनफ्लोवेल बेंचमार्क पर 98% शून्य सटीकता और 62% हासिल किया। बेदहरण एक छोटा 115 मिलियन आयाम V-JAPA मॉडल या उपरोक्त संचालन में से एक को केवल एक सप्ताह में दिखाता है। ये निष्कर्ष कल्पना को चुनौती देते हैं कि सहज ज्ञान युक्त भौतिकी के लिए जन्मजात मुख्य जीनोलेज की आवश्यकता होती है और शारीरिक तर्क को विकसित करने में अमूर्त भविष्यवाणी मॉडल की संभावना पर प्रकाश डाला जाता है।
विकासात्मक मनोचिकित्सा। परंपरागत रूप से शिशुओं पर लागू होता है, यह विधि भौतिक संकेतकों द्वारा आश्चर्यजनक प्रतिक्रियाओं जैसे कि हड़ताली समय को आश्चर्यजनक रूप से प्रतिक्रिया करता है। हाल ही में, यह दृश्य दृश्यों के साथ जोड़ी को प्रस्तुत करके एआई सिस्टम में विस्तारित किया गया है, जहां व्यक्ति में शारीरिक असंभवता शामिल है, जैसे कि एक गेंद ऑक्यूलर के पीछे गायब हो जाती है। V-JAPA आर्किटेक्चर, जिसे वीडियो भविष्यवाणी कार्यों के लिए डिज़ाइन किया गया है, वीडियो के मुखौटे भागों की भविष्यवाणी करके उच्च-स्तरीय अभ्यावेदन सीखता है। यह दृष्टिकोण मॉडल को पूर्वनिर्धारित अमूर्तता के आधार पर ऑब्जेक्ट beject dynamics की एक निहित समझ विकसित करने में सक्षम बनाता है, जैसे कि वीडियो अनुक्रमों में अप्रत्याशित भौतिक घटनाओं की अपेक्षा और प्रतिक्रिया करने की क्षमता।
V-JP ने बेंचमार्क सहज ज्ञान युक्त भौतिकी, आपत्ति बोझ स्थिरता, निरंतरता और गुरुत्वाकर्षण जैसे डेटासेट जैसे डेटासेट जैसे कि INTPHYS, GRASP और INFLOWL-LABs जैसे गुणों का मूल्यांकन किया। VideEmiv2 और मल्टीमॉडल भाषा मॉडल अन्य मॉडलों की तुलना में काफी अधिक सटीक थे, जैसे कि Qwen2-VL-7B और GEMINI 1.5 PRO, V-JAPA, जो दिखाता है कि संरचनात्मक प्रतिनिधित्व स्थान में शिक्षा भौतिक तर्क को बढ़ाती है। सांख्यिकीय विश्लेषण ने कई संपत्तियों में परीक्षण नेटवर्क पर अपनी उत्कृष्टता की पुष्टि की, यह कहते हुए कि आत्म-सम्मान वीडियो भविष्यवाणी वास्तविक दुनिया के भौतिकी की समझ त्रिज्या को बढ़ावा देती है। ये निष्कर्ष मौजूदा एआई मॉडल के लिए सहज भौतिकी की चुनौती को उजागर करते हैं और संकेत देते हैं कि विद्वानों के प्रतिनिधित्व के स्थान पर सीखी गई शिक्षा एआई के भौतिक तर्क को बेहतर बनाने की कुंजी है।
अंत में, इस अध्ययन को पता चला है कि कैसे उन्नत गहरी डंडा शिक्षा मॉडल सहज ज्ञान युक्त भौतिकी की समझ विकसित करते हैं। यह मॉडल विद्वानों की प्रस्तुति स्थान में एक भविष्य कहनेवाला फ़ंक्शन का उपयोग करके प्राकृतिक वीडियो पर वी-जापा को मुद्रित करके एक फ़ंक्शन-विशिष्ट अनुकूलन के बिना सहज ज्ञान युक्त भौतिकी की समझ को दर्शाता है। परिणाम बताते हैं कि यह क्षमता हार्डवाइड Jnowledge के बजाय सामान्य शिक्षा सिद्धांतों से है। हालांकि, संभावित प्रशिक्षण सीमाओं और लघु वीडियो प्रसंस्करण के कारण, वी-जापा ऑब्जेक्ट बग इंटरैक्शन के साथ संघर्ष करता है। मॉडल मेमोरी को बढ़ाने और कार्रवाई-आधारित शिक्षा को शामिल करने से प्रदर्शन में सुधार हो सकता है। भविष्य के अनुसंधान दृश्य डेटा पर प्रशिक्षित मॉडल की जांच कर सकते हैं, जैसे कि शिशु जो एआई में शारीरिक तर्क के लिए भविष्य कहनेवाला शिक्षा की संभावना को मजबूत करते हैं।
जाँच करना कागज़। इस शोध के लिए सभी क्रेडिट इस परियोजना के शोधकर्ताओं को जाते हैं। इसके अलावा, हमें फॉलो करने के लिए स्वतंत्र महसूस करें ट्विटर और हमसे जुड़ने के लिए मत भूलना 75 k+ ml सबमिटेड।
। अनुशंसित रीडिंग- एलजी एआई रिसर्च नेक्सस प्रकाशित करता है: एक उन्नत प्रणाली एआई एजेंट एआई सिस्टम और डेटा अनुपालन मानकों को एआई डेटासेट में कानूनी चिंताओं को खत्म करने के लिए
मार्कटेकपोस्ट और आईआईटी मद्रास में एक परामर्श इंटर्न सना हसन, वास्तविक दुनिया की चुनौतियों को पार करने के लिए प्रौद्योगिकी और एआई को लागू करने के बारे में उत्साहित हैं। व्यावहारिक समस्याओं को हल करने में उत्सुक रुचि के साथ, यह एआई और वास्तविक जीवन समाधानों के चौराहे के लिए एक नया परिप्रेक्ष्य लाता है।



