

सत्यापित रिवार्ड्स (RLVR) से सुदृढीकरण शिक्षा हाल ही में प्रत्यक्ष पर्यवेक्षण के बिना भाषा के मॉडल में तर्क क्षमता बढ़ाने के लिए एक आशाजनक विधि के रूप में उभरी है। इस दृष्टिकोण ने गणित और कोडिंग में महत्वपूर्ण सफलता दिखाई है, जहां तर्क स्वाभाविक रूप से एक संरचित समस्या के साथ आयोजित करता है। जबकि अध्ययनों से पता चला है कि अकेले आरएलवीआर आत्म-विकास तर्क को जन्म दे सकता है, अनुसंधान इन तकनीकी क्षेत्रों तक बहुत सीमित है। RLVR का विस्तार करने के प्रयासों ने कृत्रिम डेटासेट का आविष्कार किया है, जैसे कि अनुक्रमिक कार्यों और ऑब्जेक्ट बजट गणना, संभावित दिखाते हुए, लेकिन विभिन्न डोमेन के अनुरूप चुनौती को भी रोशन करता है।
व्यापक क्षेत्रों में RLVR का विस्तार करना एक खुली चुनौती है, विशेष रूप से बहुविकल्पीय प्रश्नों (MCQA) जैसे कार्यों में, जो दवाओं सहित विभिन्न विषयों में संरचित, सत्यापित लेबल प्रदान करता है। हालांकि, गणित और कोडिंग के विपरीत, जिसमें खुले अंतिम उत्तर स्थान के साथ जटिल तर्क शामिल हैं, MCQA कार्यों में आमतौर पर पूर्व निर्धारित उत्तर विकल्प होते हैं, जो आरएलवीआर के लाभों का प्रभावी रूप से अनुवाद करते हैं। यह सीमा विशेष रूप से चिकित्सा तर्क कार्यों में प्रासंगिक है, जहां मॉडल को सटीक उत्तर देने के लिए जटिल नैदानिक Junowledge का पता लगाना चाहिए, वह क्षेत्र जो मौजूदा AI सिस्टम के लिए मुश्किल साबित हुआ है।
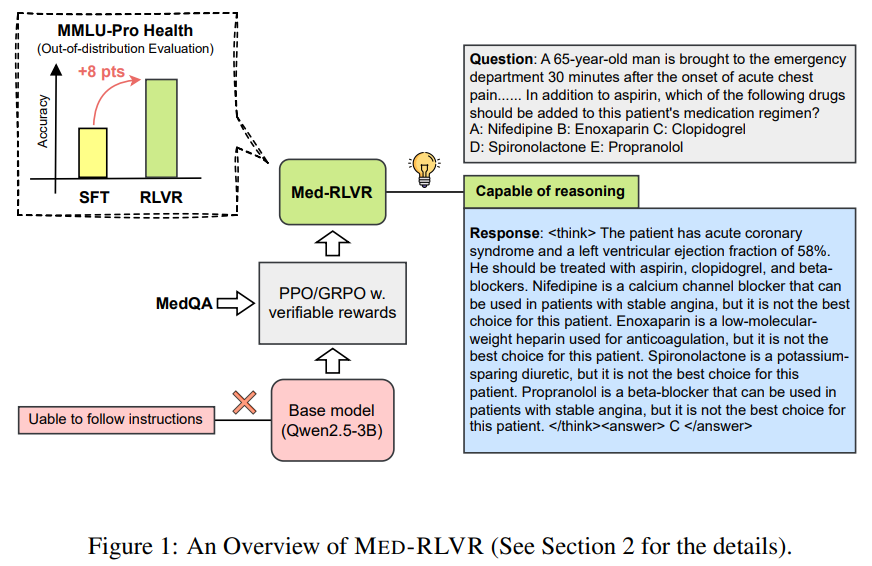
MicroS .FFT अनुसंधान शोधकर्ता यह जांचते हैं कि क्या चिकित्सा तर्क RLVR द्वारा बाहर आ सकते हैं। वे MED-RLVR का परिचय देते हैं, मेडिकल MCQA डेटा प्रदान करते हैं जो चिकित्सा डोमेन में RLVR की प्रभावशीलता का मूल्यांकन करते हैं। उनके निष्कर्षों से पता चलता है कि RLVR गणित और कोडिंग से परे फैली हुई है, देखे गए फाइन-ट्यूनिंग (SFT) -Distributing कार्यों में तुलनात्मक कार्य प्राप्त करना, जबकि आठ प्रतिशत मुद्दों द्वारा वितरित किए गए आउट-ऑफ-डिस्ट्रिब्यूशन जनरल में काफी सुधार हुआ है। प्रशिक्षण की गतिशीलता का विश्लेषण करते हुए, वे देखते हैं कि तर्क क्षमताएं स्पष्ट पर्यवेक्षण के बिना 3 बी-पैरामीटर बेस मॉडल में उभरती हैं, जो चिकित्सा जैसे Jonoweltge- गहन क्षेत्रों के क्षेत्र में RLVR की संभावना को रोशन करती है।
R.L. पर्यावरण के साथ बातचीत के माध्यम से पुरस्कारों को अधिकतम करने के लिए एजेंट को प्रशिक्षित करके निर्णय लेना सबसे अच्छा है। मानव वरीयताओं के साथ आउटपुट को संरेखित करने और स्पष्ट निगरानी के बिना तर्क को आगे बढ़ाने के लिए इसे प्रभावी रूप से भाषा मॉडल डेलो पर लागू किया गया है। इस अध्ययन नीति मॉडल को प्रशिक्षित करने के लिए समीपस्थ नीति ने इष्टतम ptimization (PPO) को नियोजित किया, जिसमें प्रशिक्षण को स्थिर करने के लिए क्लिप किए गए उद्देश्य को शामिल किया गया है। नियम-आधारित पुरस्कार फ़ंक्शन का उपयोग करते हुए, MED-RLVR आउटपुट शुद्धता और प्रारूप मान्यता के आधार पर पुरस्कार प्रदान करता है। अतिरिक्त निगरानी के बिना, मॉडल पिछले RLVR अध्ययन में गणितीय तर्क के समान उभरते चिकित्सा तर्क को दर्शाता है, जो संरचित डोमेन से परे RLVR की क्षमता को रोशन करता है।
Mercue-USML डेटासेट, जिसमें बहु-पसंद चिकित्सा परीक्षा प्रश्न शामिल हैं, का उपयोग MED-RLVR को प्रशिक्षित करने के लिए किया जाता है। मानक चार-तत्व संस्करण के विपरीत, यह डेटासेट अधिक उत्तर विकल्प देकर एक बड़ी चुनौती प्रस्तुत करता है। प्रशिक्षण सुदृढीकरण शिक्षा के लिए OpenRLHF का उपयोग करके QWEN2.5-3B मॉडल पर आधारित है। SFT की तुलना में, MED-RLVR, विशेष रूप से MMLU-PRO-HEALTH DATASET पर, बेहतर के सामान्य सामान्यीकरण को दर्शाता है। विश्लेषण से लॉजिक इवोल्यूशन के छह चरणों का पता चलता है: प्रारूप विफलता, वर्बोज़ आउटपुट, पुरस्कार हैकिंग और री -इंट्रिटेड लॉजिक। गणित या कोडिंग कार्यों के विपरीत, कोई भी स्व-मान्यता व्यवहार (“AHA-MOMENTS”) नहीं देखा गया था, जो छोटी तर्क श्रृंखलाओं को दंडित करके या लंबी बिल्लियों के साथ ठीक-ठाक-ट्यूनिंग द्वारा संभावित सुधार का संकेत देता है।
अंत में, अध्ययन चिकित्सा में MCQA पर केंद्रित है, मूल्यांकन के लिए एक नियंत्रित सेटिंग प्रदान करता है। हालांकि, MCQA वास्तविक दुनिया के कार्यों की जटिलता को पूरी तरह से कैप्चर नहीं करता है जैसे कि ओपन-टेक्स्ट उत्तर, रिपोर्ट पीढ़ी या चिकित्सा संवाद। इसके अलावा, यूनीमॉडल दृष्टिकोण मल्टीमॉडल डेटा को एकीकृत करने के लिए मॉडल की क्षमता को सीमित करता है, जो नैदानिक अनुप्रयोगों के लिए महत्वपूर्ण है। भविष्य के काम में इन सीमाओं को दूर किया जाना चाहिए। MED-RLVR, सत्यापित पुरस्कारों के साथ सुदृढीकरण शिक्षा के आधार पर, इन-डिस्ट्रिब्यूशन कार्यों पर SFT से मेल खाता है और वितरण के सामान्यीकरण में सुधार करता है। जब चिकित्सा तर्क स्पष्ट पर्यवेक्षण के बिना उभरता है, तो पुरस्कार हैकिंग जैसी चुनौतियां जारी रहती हैं, जटिल तर्क और मल्टीमॉडल एकीकरण की अधिक खोज की आवश्यकता को उजागर करती हैं।
जाँच करना कागज़। इस शोध के लिए सभी श्रेय इस परियोजना के शोधकर्ताओं को जाते हैं। इसके अलावा, हमें फॉलो करने के लिए स्वतंत्र महसूस करें ट्विटर और हमसे जुड़ने के लिए मत भूलना 85 k+ ml सबमिटेड।
मार्कटेकपोस्ट और आईआईटी मद्रास में एक परामर्श इंटर्न सना हसन, वास्तविक दुनिया की चुनौतियों को दूर करने के लिए प्रौद्योगिकी और एआई को लागू करने के बारे में उत्साहित हैं। व्यावहारिक समस्याओं को हल करने में अधिक रुचि के साथ, यह एआई और वास्तविक जीवन समाधानों के चौराहे के लिए एक नया परिप्रेक्ष्य लाता है।


