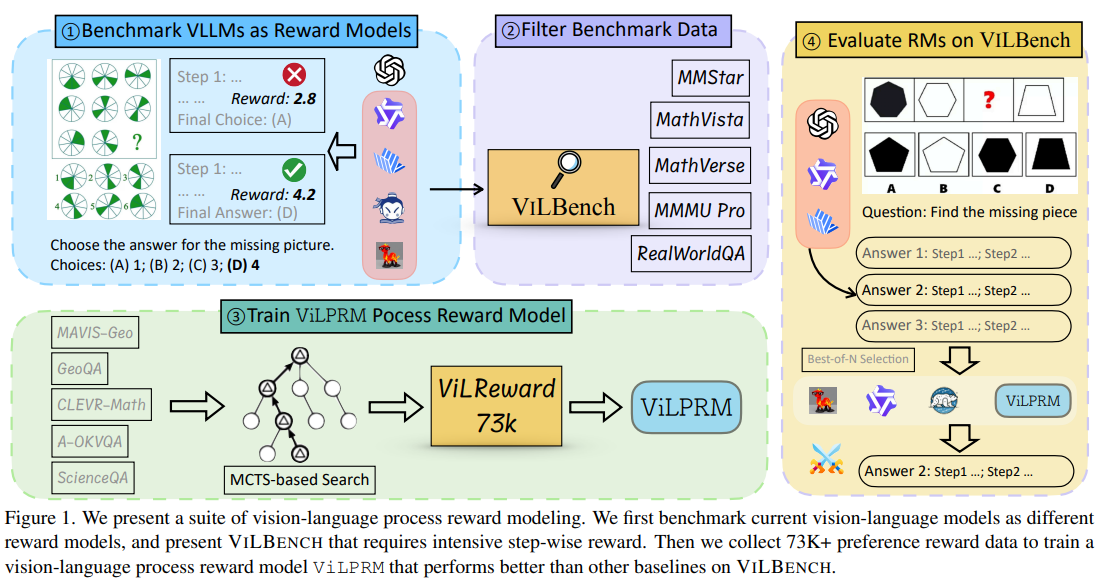

प्रक्रिया वाले पुरस्कार मॉडल (PRM) जटिल कार्यों के लिए एक प्रभावी तर्क पथ का चयन करने में मदद करते हैं, मॉडल के उत्तरों के लिए एक ठीक-ठीक दानेदार, कदम-वार प्रतिक्रिया। आउटपुट पुरस्कार मॉडल (ORM) के विपरीत, जो अंतिम आउटपुट के आधार पर उत्तरों का मूल्यांकन करता है, PRM प्रत्येक चरण पर विस्तृत मूल्यांकन प्रदान करता है, जिससे वे विशेष रूप से तर्क-गहन अनुप्रयोगों के लिए मूल्यवान हैं। जबकि PRMs को भाषा के कार्यों में व्यापक रूप से अध्ययन किया गया है, मल्टीमॉडल सेटिंग्स में उनका आवेदन बहुत अनिश्चित है। अधिकांश दृष्टि-भाषा इनाम मॉडल अभी भी ORM दृष्टिकोण पर निर्भर करते हैं, जो आगे के शोध की आवश्यकता पर प्रकाश डालता है कि कैसे PRMs मल्टीमॉडल शिक्षा और तर्क को बढ़ा सकते हैं।
मौजूदा इनाम बेंचमार्क मुख्य रूप से पाठ-आधारित मॉडल पर केंद्रित है, कुछ विशेष रूप से पीआरएम के लिए डिज़ाइन किए गए हैं। दृष्टि-भाषा डोमेन में, मूल्यांकन के तरीके आमतौर पर व्यापक मॉडल क्षमताओं का मूल्यांकन करते हैं, जिनमें जूनोवेलेज, लॉजिक, नेस पेंटिंग और सुरक्षा शामिल हैं। वीएल-पुरस्कृत बैंक पहला बेंचमार्क है जिसमें जूनोवलेज-इंटेंसिव विजन-लैंग्वेज कार्यों को बेहतर बनाने के लिए सुदृढीकरण सीखने का डेटा शामिल है। इसके अतिरिक्त, मल्टीमॉडल इनम्बेन्चर मानक दृश्य प्रश्न (WQA) कार्यों से परे मूल्यांकन मानदंड को बढ़ाता है, छह प्रमुख क्षेत्रों को कवर करता है – विशेषज्ञ एनोडेन द्वारा सुधार, चयन, लॉगजेज, लॉजिक, सुरक्षा और WQA -। यह बेंचमार्क मल्टीमॉडल शिक्षा के लिए अधिक प्रभावी पुरस्कार मॉडल विकसित करने के लिए नींव प्रदान करता है।
यूसी सांता क्रूज़, यूटी डलास और अमेज़ॅन रिसर्च के शोधकर्ताओं ने वीएलएमएस बेंचमार्क को कई कार्यों में ओआरएम और पीआरएम के रूप में बनाया, यह दर्शाता है कि न तो लगातार दूसरे को धक्का देता है। मूल्यांकन अंतराल को दूर करने के लिए, उन्होंने विल्बन्च, एक बेंचमार्क प्रस्तुत किया, जिसमें चरण -वाइज रिवार्ड प्रतिक्रिया की आवश्यकता होती है, जहां GPT -4O केवल 27.3% सटीकता को चेन -थिंकिंग के साथ प्राप्त करता है। इसके अलावा, उन्होंने एन्हांस्ड ट्री-सर्च एल्गोरिथ्म एकत्र किया। उनका अध्ययन विज़न-लैंग्वेज अवार्ड मॉडलिंग की अंतर्दृष्टि प्रदान करता है और मल्टीमॉडल चरणों के आकलन में चुनौतियों को उजागर करता है।
वीएलएम विभिन्न कार्यों में तेजी से प्रभावी हो रहा है, खासकर जब परीक्षण-समय स्केलिंग के लिए मूल्यांकन किया जाता है। पांच विज़न-लैंग्वेज डेटासेट पर उनके कदमों के अनुसार आलोचना का विश्लेषण करने के लिए एलएलएम-ए-ए-ए-क्यूज़ दृष्टिकोण का उपयोग करके सात मॉडलों को बेंचमार्क किया गया था। सर्वश्रेष्ठ-एफ-एन (हड्डी) सेटिंग का उपयोग किया गया था, जहां जीपीटी -4 ओ द्वारा निर्मित वीएलएमएस-जनित वीएलएम। मुख्य निष्कर्ष घोषणा करते हैं कि ज्यादातर मामलों में ओआरएम वास्तविक दुनिया के कार्यों को छोड़कर पीआरएम से बेहतर प्रदर्शन करते हैं। इसके अतिरिक्त, मजबूत वीएलएम हमेशा एक इनाम मॉडल के रूप में उत्कृष्ट नहीं होता है, और ओआरएम और पीआरएम के बीच एक हाइब्रिड दृष्टिकोण सबसे अच्छा है। इसके अलावा, VLM दृश्य की तुलना में अधिक पाठ-सना हुआ कार्यों से लाभान्वित होता है, विशेष दृष्टि-भाषा इनाम मॉडल की आवश्यकता को पूरा करता है।
VILPRM की प्रभावशीलता का मूल्यांकन करने के लिए, विभिन्न RM और समाधान नमूने का उपयोग करके Vilbanch पर प्रयोग किए गए थे। यह अध्ययन QWEN2.5-VL-3B, InternVL -2.5-8B, GPT-4O, और O1 सहित कई VLM में प्रभाव की तुलना करता है। परिणाम बताते हैं कि पीआरएम आमतौर पर ओआरएम को धक्का देता है, 1.4%सटीकता में सुधार करता है, हालांकि ओ 1 के उत्तर सीमित विवरण के कारण न्यूनतम अंतर दिखाते हैं। VILPRAMA URSA सहित अन्य PRM, 0.9%से अधिक हो गए, जो उत्तर की पसंद में सबसे अच्छी प्रासंगिकता दिखा रहा है। इसके अतिरिक्त, निष्कर्ष बताते हैं कि मौजूदा वीएलएम एक इनाम मॉडल के रूप में पर्याप्त मजबूत नहीं है, जो गणितीय तर्क कार्यों से अच्छी तरह से प्रदर्शित करने वाले एक विशिष्ट दृष्टि-भाषा पीआरएम की आवश्यकता पर प्रकाश डालता है।
अंत में, विज़न-लैंग्वेज पीआरएम अच्छा प्रदर्शन करते हैं जब तर्क के कदम साझा किए जाते हैं, जैसा कि गणित जैसे संरचनात्मक कार्यों में पाया जाता है। हालांकि, अस्पष्ट कदम वर्गों वाले कार्यों में, पीआरएम सटीकता को कम कर सकते हैं, विशेष रूप से दृश्य-बल के मामलों में। सभी समान प्रदर्शन में सुधार करने के बजाय प्रमुख चरणों को प्राथमिकता दें। इसके अलावा, वर्तमान मल्टीमॉडल पुरस्कार मॉडल सामान्यीकरण के साथ संघर्ष करते हैं, क्योंकि विशेष डोमेन पर प्रशिक्षित पीआरएम अक्सर दूसरों में विफल हो जाते हैं। विभिन्न डेटा स्रोतों और अनुकूली इनाम के तरीकों को शामिल करने के लिए प्रशिक्षण बढ़ाना महत्वपूर्ण है। Willverward -73K की शुरूआत PRM की सटीकता में 3.3%में सुधार करती है, लेकिन मजबूत मल्टीमॉडल मॉडल को स्टेप स्प्लिटिंग और इवैल्यूएशन फ्रेमवर्क में और प्रगति की आवश्यकता होती है।
जाँच करना कागज़। इस शोध के लिए सभी श्रेय इस परियोजना के शोधकर्ताओं को जाते हैं। इसके अलावा, हमें फॉलो करने के लिए स्वतंत्र महसूस करें ट्विटर और हमसे जुड़ने के लिए मत भूलना 85 k+ ml सबमिटेड।
। ।
मार्कटेकपोस्ट और आईआईटी मद्रास में एक परामर्श इंटर्न सना हसन, वास्तविक दुनिया की चुनौतियों को दूर करने के लिए प्रौद्योगिकी और एआई को लागू करने के बारे में उत्साहित हैं। व्यावहारिक समस्याओं को हल करने में उत्सुक रुचि के साथ, यह एआई और वास्तविक जीवन समाधानों के चौराहे के लिए एक नया परिप्रेक्ष्य लाता है।