
बड़े भाषा मॉडल डेलो (एलएलएमएस) ने असाधारण समस्या, अभी तक जटिल तर्क कार्यों या प्रतिस्पर्धा-स्तरीय गणित या जटिल कोड जनरेशन-रेमैन को चुनौती देने की क्षमता को हल करने की क्षमता दिखाई है। ये कार्य बड़े समाधान स्थानों और एहतियाती उपायों के विचार के माध्यम से एक विशिष्ट शोधकर्ता की मांग करते हैं। मौजूदा तरीके, सटीकता में सुधार करते समय, अक्सर रचना गणना, कठोर खोज रणनीतियों की लागत से पीड़ित होते हैं और विभिन्न समस्याओं को सामान्य करने में कठिनाई होती है। इस पत्र में शोधकर्ताओं ने एक नई संरचना पेश की, कारक LLMS इन सीमाओं को फिर से कल्पना करता है कि कैसे पदानुक्रमित, टेम्पलेट-निर्देशित रणनीतियों का उपयोग करके तर्क चरणों की योजना और कार्यान्वयन करें।
LLM तर्क बढ़ाने के लिए हाल के दृष्टिकोण दो श्रेणियों में आते हैं: जानबूझकर आविष्कार और इनाम। ट्री ऑफ़ आइडियाज (TOT) जैसी प्रौद्योगिकियां LLM को कई लॉजिक पथों का पता लगाने में सक्षम बनाती हैं, जबकि मोंटे कार्लो ट्री सर्च (MCTS) प्रक्रिया पुरस्कार मॉडल (PRM) द्वारा निर्देशित चरणों में समस्याओं को संसाधित करती हैं। हालांकि प्रभावी, इन विधियों को अत्यधिक नमूनों और मैनुअल खोज डिजाइन के कारण खराब तरीके से बढ़ाया जाता है। उदाहरण के लिए, MCT को हजारों संभावित चरणों द्वारा दोहराया जाना चाहिए, जिससे यह वास्तविक दुनिया के अनुप्रयोगों के लिए गणना की जाती है। इस बीच, Redeie Procurement-UG Ganted Generation (RAG) जैसे तरीके बफर को फो-लीवरेज समस्या को सुलझाने के नमूनों को स्टोर करते हैं, लेकिन कई नमूनों के अनुकूल होने के लिए संघर्ष करते हैं, जटिल विचारों में उनकी उपयोगिता को सीमित करते हैं।
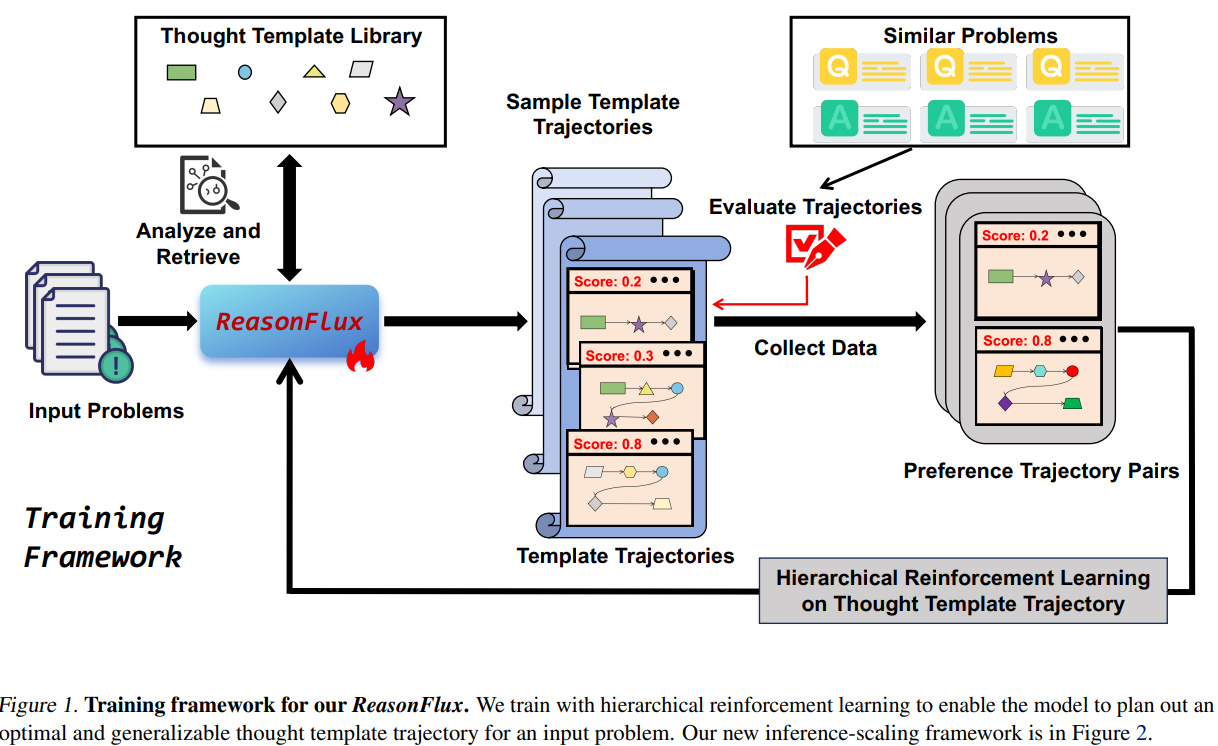
Rizflux एक संरचित ढांचे का परिचय देता है जो तर्क पथ की योजना और शुद्धि के लिए पदानुक्रमित सुदृढीकरण सीखने (HRL) के साथ उच्च-स्तरीय विचार नमूनों के ठीक किए गए पुस्तकालय को जोड़ता है। व्यक्तिगत चरणों को izing करने के बजाय, यह सर्वश्रेष्ठ को समायोजित करने पर ध्यान केंद्रित करता है नमूना पथसंरचित gnowledge आधार से प्राप्त अमूर्त समस्या को हल करने की रणनीति की समानता। यह दृष्टिकोण खोज स्थान की सुविधा देता है और उप -प्रोबल्स के लिए कुशल अनुकूलन को सक्षम करता है। फ्रेमवर्क में तीन मुख्य घटक शामिल हैं:
- नमूना पुस्तकालय: अनुसंधान टीम ने 500 विचार टेम्पलेट का एक पुस्तकालय बनाया, जिसमें प्रत्येक समस्या को सुलझाने की रणनीति (जैसे, “अभिन्न इष्टतम ptimization के लिए ट्राइगामेट्री विकल्प”) शामिल किया गया। टेम्प्लेट में मेटाडेटा – नाम, टी एस जीएस, विवरण और एप्लिकेशन चरण शामिल हैं – कुशल वसूली को सक्षम करना। उदाहरण के लिए, T -GED नमूना “अतार्किक फ़ंक्शन ऑप्टिमेशन ptimization” के लिए एक विशिष्ट बीजगणितीय विकल्प लागू करने के लिए LLM को मार्गदर्शन कर सकता है।
- पदानुक्रमित सुदृढीकरण शिक्षाकठिन
- रचना -आधारित दंड: बेस एलएलएम (जैसे, QWEN2.5-32B) अपने कार्यात्मक विवरणों के साथ एक नमूना मेटाडेटा संलग्न करने के लिए अच्छा है, यह सुनिश्चित करता है कि प्रत्येक नमूना कब और कैसे लागू करना है।
- नमूना तरीका इष्टतम ptimization: वरीयता सीखने का उपयोग करते हुए, मॉडल उनकी प्रभावशीलता द्वारा नमूना अनुक्रमों को रैंक करना सीखता है। किसी दिए गए समस्या के लिए, कई तरह से नमूने लिए जाते हैं, और समान समस्याओं पर उनकी सफलता दर पुरस्कारों को निर्धारित करती है। यह मॉडल को उच्च-सौर अनुक्रमों को प्राथमिकता देने के लिए प्रशिक्षित करता है, जो योजना की अपनी क्षमता में सुधार करता है।
- अनुकूली अनुमान: अनुमान के दौरान, लॉजिकल “नेविगेटर” के रूप में कार्य करता है, प्रासंगिक नमूनों को प्राप्त करने के लिए समस्या का विश्लेषण करता है, और मध्यवर्ती परिणामों के आधार पर गतिशील रूप से मार्ग को समायोजित करता है। उदाहरण के लिए, यदि “बहुभुज कारक” से जुड़ा एक कदम एक अप्रत्याशित अवरोध देता है, तो सिस्टम “बैरियर प्रचार” नमूने को जन्म दे सकता है। योजना और निष्पादन के बीच यह आवर्तक अंतर एक मानवीय समस्या को हल किया गया दर्पण देता है, जहां आंशिक समाधान बाद के चरणों की रिपोर्ट करते हैं।

रिज़फ्लक्स का मूल्यांकन मेथ, एईएम और ओलंपियाडबेंच जैसे प्रतियोगिता-स्तरीय बेंचमार्क पर किया गया था, दोनों आउटपोस्ट फ्रंटियर मॉडल (जीपीटी -4 ओ, क्लाउड) और विशेष ओपन-सफर मॉडल (डीईपीसीसी-वी 3, मेथ्रल)। मुख्य परिणामों में शामिल हैं:
- गणित पर 91.2% सटीकता।
- AEM 2024 पर 56.7%Dippic-V3 45% से अधिक और O 1-Mi के साथ मेल खाता है।
- 63.3% ओलंपियाडबेंचपिछले तरीकों पर 14% में सुधार करें।
इसके अलावा, संरचित टेम्पलेट लाइब्रेरी ने मजबूत सामान्यीकरण का प्रदर्शन किया: जब विभिन्न समस्याओं पर लागू होता है, तो यह प्रत्यक्ष तर्क का उपयोग करके बड़े समकक्षों को आगे बढ़ाने के लिए छोटे मॉडल (जैसे, 7 बी मापदंडों) को तेज करता है। इसके अलावा, कारण ने एक उत्कृष्ट अनुसंधान-अवशोषित संतुलन प्राप्त किया, जिसके लिए एमसीटी की तुलना में 40% कम गणना चरणों और जटिल कार्यों (चित्रा 5) पर सर्वश्रेष्ठ-एन की आवश्यकता होती है।
सारांश में, Logiflux फिर से परिभाषित करता है कि LLMS चरण-दर-चरण कार्यान्वयन द्वारा उच्च-स्तरीय रणनीति तय करके जटिल तर्क से कैसे संपर्क करता है। इसका पदानुक्रमित टेम्पलेट सिस्टम सटीकता और अनुकूलनशीलता में सुधार करते समय गणना ओवरहेड को कम कर देता है, मौजूदा तरीकों में महत्वपूर्ण अंतराल को संबोधित करता है। संरचित gnowledge और गतिशील योजना का लाभ देकर, फ्रेमवर्क कुशल, स्केलेबल लॉजिक के लिए एक नया मानक निर्धारित करता है-जो प्रस्ताव करता है कि छोटे, अच्छी तरह से निर्देशित मॉडल भी सबसे बड़े फ्रंटियर सिस्टम को प्रतिद्वंद्वी कर सकते हैं। यह नवाचार शिक्षा से स्वचालित कोड जनरेशन तक एक संसाधन-सीमित वातावरण में उन्नत तर्क को व्यवस्थित करने का एक तरीका खोलता है।
जाँच करना कागज़। इस शोध के लिए सभी श्रेय इस परियोजना के शोधकर्ताओं को जाते हैं। इसके अलावा, हमें फॉलो करने के लिए स्वतंत्र महसूस करें ट्विटर और हमसे जुड़ने के लिए मत भूलना 75 k+ ml सबमिटेड।
। अनुशंसित ओपन-सीरस एआई प्लेटफॉर्म: ‘इंटेलिजेंट एक ओपन सोर्स मल्टी-एजेंट फ्रेमवर्क है जो जटिल वार्तालाप एआई सिस्टम का मूल्यांकन करता है” (बिस्तर)
विनीत कुमार मार्केटचपोस्ट में एक परामर्श इंटर्न है। वह वर्तमान में भारतीय इंस्टीट्यूट ऑफ कानपुर टेक्नोलॉजी फेक्नोलॉजी (IIT) से बीएस का पीछा कर रहे हैं। वह मशीन लर्निंग उत्साही है। यह अनुसंधान और गहरी शिक्षा, कंप्यूटर दृष्टि और संबंधित क्षेत्रों में नवीनतम प्रगति के बारे में उत्साही है।
✅ (अनुशंसित) हमारे टेलीग्राम चैनल में शामिल हों