

लॉजिक लैंग्वेज मॉडल डेलो ने अनुमान के दौरान लंबे समय तक श्रृंखला-योग्य अनुक्रमों का उत्पादन करके प्रदर्शन को बढ़ाने की क्षमता दिखाई है, जो कि बढ़ी हुई गणनाओं को प्रभावी ढंग से लाभान्वित करती है। हालांकि, मुख्य सीमा तर्क की लंबाई पर नियंत्रण की कमी है, जिससे गिनती संसाधनों को प्रभावी ढंग से आवंटित करना मुश्किल हो जाता है। कुछ मामलों में, मॉडल अत्यधिक लंबे आउटपुट का उत्पादन करते हैं, गणना को बर्बाद करते हैं, जबकि दूसरों में, वे बहुत जल्द रुक जाते हैं, जिससे सब -डिस्प्ले डिस्प्ले होता है। मौजूदा दृष्टिकोण अक्सर प्रभाव को कम करते हैं, जैसे कि आउटपुट लंबाई को नियंत्रित करने के लिए “वेटिंग” या “अंतिम उत्तर” जैसे विशेष टोकन को लागू करना। सामान्य पाठ पीढ़ी के विपरीत, तर्क कार्यों को गणना की दक्षता और सटीकता के बीच संतुलन की आवश्यकता होती है, जो नियंत्रण की एक निश्चित लंबाई की आवश्यकता पर प्रकाश डालता है।
पिछले शोध ने एक परीक्षण-समय स्केलिंग रणनीति का आविष्कार किया है, जो दिखाता है कि लंबे समय तक तर्क श्रृंखला या समानांतर नमूने गणितीय समस्या को हल करने और कोड जनरेशन जैसे जटिल तर्क कार्यों में प्रभाव में सुधार करते हैं। हालांकि, वर्तमान तरीकों से तर्क की लंबाई पर दंड का अभाव है, जिससे अयोग्यता हो जाती है। जबकि आउटपुट लंबाई नियंत्रण पर पिछले काम में, मुख्य रूप से निर्देश-विच्छेदित मॉडल या सामान्य पाठ पीढ़ी पर ध्यान केंद्रित करते हुए, तर्क मॉडल पूर्वानुमान लंबाई के गतिशील समायोजन की आवश्यकता के कारण अद्वितीय चुनौतियों का सामना करते हैं। हाल के प्रयास जैसे कि बजट-उदाहरण में कटौती, तर्क प्रासंगिकता को बाधित करना और सटीकता में बाधा। इन अंतरालों को हटाकर, यह शोध स्पष्ट रूप से तर्क की लंबाई को नियंत्रित करने के लिए एक विधि का प्रतिनिधित्व करता है, प्रभाव बनाए रखते हुए izing लागतों को बढ़ाता है।
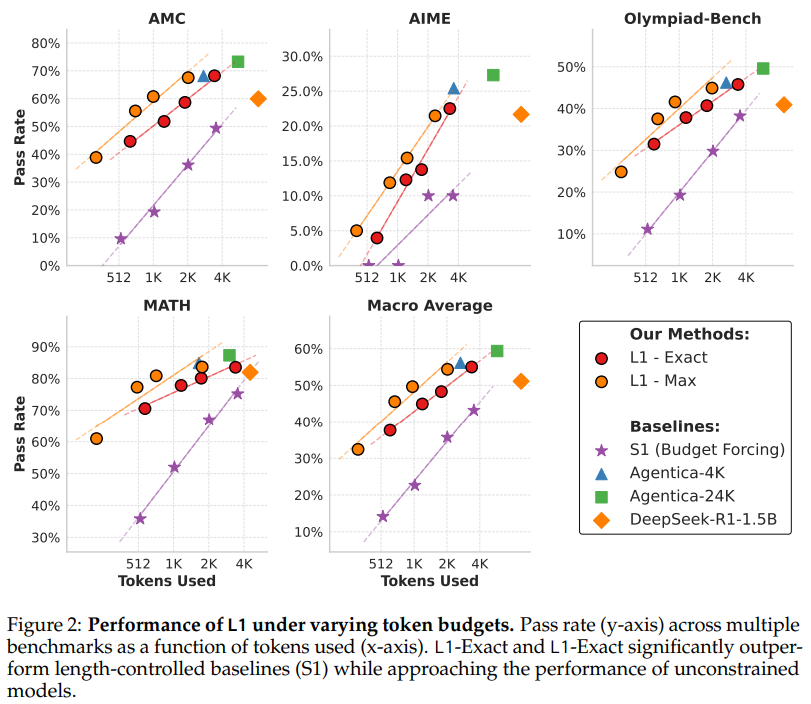
कार्नेगी मेलन विश्वविद्यालय के शोधकर्ता लंबाई-नियंत्रित नीति ऑप्टिमाइज़ेशन (LCPO) का परिचय देते हैं, एक सुदृढीकरण शिक्षा दृष्टिकोण जो उपयोगकर्ता-परिभाषित लंबाई बाधा की सटीकता और अनुपालन सुनिश्चित करके तर्क मॉडल को बढ़ाता है। LCPO- प्रशिक्षित मॉडल, जैसे L1, प्रभावी रूप से संकेत-आधारित बाधा द्वारा तर्क की लंबाई को समायोजित करके कम्प्यूटेशनल लागत और प्रदर्शन को समायोजित करता है। L1s S1 विधि से अधिक है और GPT -4O भी एक ही तर्क लंबाई पर चलता है। इसके अलावा, LCPO तार्किक तर्क और JNowledge बेंचमार्क जैसे MMLU में मॉडल सामान्यीकरण में सुधार करता है। विशेष रूप से, LCPO के साथ प्रशिक्षित मॉडल विभिन्न कार्यों में कुछ लंबाई नियंत्रण को बनाए रखते हुए उच्च सटीकता प्राप्त करते हैं, मजबूत छोटी श्रृंखला-सोच क्षमताओं को प्रदर्शित करते हैं।
पारंपरिक तर्क मॉडल में आउटपुट लंबाई को नियंत्रित करने के तरीकों की कमी होती है, जिससे गणना बजट का प्रबंधन करना मुश्किल हो जाता है। LCPO ने प्रॉम्प्ट में दिए गए लक्ष्य लंबाई पर मॉडल को कंडीशनिंग करके इसे संबोधित किया। मॉडल को पुरस्कार समारोह संतुलित सटीकता और लंबाई के अवरोध के अनुपालन के साथ आरएल के उपयोग के साथ प्रशिक्षित किया जाता है। ये परिणाम दो प्रकारों में होते हैं: L1-acact, जो लक्ष्य की लंबाई और L1-MAP से कसकर मेल खाता है, जो स्पष्ट रूप से अधिकतम लंबाई में रहता है। L1-MAX शुद्धता को पसंद करते समय राहत की अनुमति देता है। यह विधि तर्क प्रदर्शन को ptimizing द्वारा दक्षता बढ़ाती है जबकि गणना लागत सुव्यवस्थित रहती है।
प्रस्तावित LCPO विधि (L1) विभिन्न बेंचमार्क में लंबाई-नियंत्रित पाठ पीढ़ी में सबसे अच्छा प्रदर्शन दिखाती है। L1-EXT और L1-MAX लगातार बेसलाइन मॉडल से बेहतर प्रदर्शन करते हैं जो एक विशिष्ट टोकन बाधा को बनाए रखते हैं। S1 की तुलना में, L1 100% से अधिक प्रासंगिक लाभों में कटौती के बिना तर्क श्रृंखलाओं के लिए प्रभावी रूप से अनुकूलित करके 20-25% प्राप्त करता है। L1, डोमेन को आउट-ऑफ-डाउमन कार्यों में अच्छी तरह से सामान्य किया जाता है, जो मजबूत प्रदर्शन स्केलिंग करता है। यह गणितीय तर्क कार्यों में न्यूनतम विचलन के साथ, लंबाई के अनुपालन में उच्च परिशुद्धता बनाए रखता है। इसके अतिरिक्त, L1 मध्यवर्ती तर्क चरणों और अंतिम आउटपुट के बीच एक कुशल संतुलन बनाए रखते हुए आत्म-सुधार और निष्कर्ष के लिए अधिक टोकन आवंटित करते हुए, अनुकूली तर्क रणनीति को नियोजित करता है।
अंत में, अध्ययन LCPO, एक सुदृढीकरण सीखने की विधि प्रस्तुत करता है जो भाषा मॉडल में तर्क श्रृंखलाओं की लंबाई पर सटीक नियंत्रण को सक्षम करता है। LCPOS का उपयोग करते हुए, हम L1 को प्रशिक्षित करते हैं, एक लॉजिक मॉडल जो सटीकता izing को ptiming करते हुए उपयोगकर्ता-परिभाषित लंबाई बाधाओं से चिपक जाता है। L1 पिछले लंबाई-नियंत्रण दृष्टिकोणों से अधिक है, गणितीय तर्क में 100% से अधिक प्रासंगिक और 20% से अधिक पूर्ण सुधार प्राप्त करता है। यह आउट-ऑफ-डोमन अच्छी तरह से काम करता है और एक ही लंबाई में GPT-4O जैसे बड़े मॉडल को धक्का देते हुए, छोटी श्रृंखला-सोच में अप्रत्याशित रूप से उत्कृष्ट है। LCPO सरल त्वरित-आधारित लंबाई नियंत्रण द्वारा गणना की लागत और सटीकता को संतुलित करने के लिए एक स्केलेबल और कुशल दृष्टिकोण प्रदान करता है।
जाँच करना कागज पर मॉडल, हग फेस और गिथब पेज। इस शोध के लिए सभी श्रेय इस परियोजना के शोधकर्ताओं को जाते हैं। इसके अलावा, हमें फॉलो करने के लिए स्वतंत्र महसूस करें ट्विटर और हमसे जुड़ने के लिए मत भूलना 80K+ एमएल सबमिटेड।
। MEET PALLANT: व्यवहार दिशानिर्देशों और रनटाइम मॉनिटरिंग का उपयोग करके, अपने AI ग्राहक सेवा एजेंटों पर आवश्यक नियंत्रण और सटीकता प्रदान करने के लिए AI फ्रेमवर्क डेवलपर्स को प्रदान करने के लिए एक LLM-FIRST वार्तालाप किया गया है। 🔧 🔧 🎛 इसका उपयोग करना आसान है। और पायथन और टाइपस्क्रिप्ट में मूल ग्राहक एसडीके का उपयोग करके संचालित है।
मार्कटेकपोस्ट और आईआईटी मद्रास में एक परामर्श इंटर्न सना हसन, वास्तविक दुनिया की चुनौतियों को दूर करने के लिए प्रौद्योगिकी और एआई को लागू करने के बारे में उत्साहित हैं। व्यावहारिक समस्याओं को हल करने में अधिक रुचि के साथ, यह एआई और वास्तविक जीवन समाधानों के चौराहे के लिए एक नया परिप्रेक्ष्य लाता है।
पार्लेंट: LLMS (B ED) के साथ एक विश्वसनीय AI ग्राहक का सामना करना

