

Dippic R1 जैसे LLMS के लिए RL में हाल की प्रगति से पता चला है कि सरल प्रश्न-उत्तर-उत्तर कार्यों से भी तर्क क्षमताओं में काफी वृद्धि हो सकती है। एलएलएम के लिए पारंपरिक आरएल दृष्टिकोण अक्सर एकल-टर्न कार्यों पर निर्भर करते हैं, जहां मॉडल को उसी प्रतिक्रिया की शुद्धता के आधार पर पुरस्कृत किया जाता है। हालांकि, ये विधियाँ बिखरे हुए पुरस्कारों से पीड़ित हैं और उपयोगकर्ता प्रतिक्रिया के आधार पर अपने उत्तरों को बेहतर बनाने के लिए मॉडल को प्रशिक्षित करने में विफल रहते हैं। इन सीमाओं को दूर करने के लिए, मल्टी-टर्न आरएल दृष्टिकोणों का आविष्कार किया गया है, जिससे एलएलएमएस समस्या को हल करने के लिए कई प्रयासों को हल करने की अनुमति देता है, इस प्रकार उनके तर्क और आत्म-सुधार क्षमताओं में सुधार होता है।
पिछले कुछ अध्ययनों ने एलएलएम के लिए आरएल में योजना और आत्म-सुधार के तरीकों की जांच की है। विचारक एल्गोरिथ्म से प्रेरित, जो एजेंटों को कार्रवाई करने से पहले विकल्पों का पता लगाने में सक्षम बनाता है, कुछ दृष्टिकोण विश्व मॉडल को सीखने के बजाय कई प्रयासों की अनुमति देकर एलएलएम तर्क को बढ़ाते हैं। स्कोर जैसे तरीकों जैसे कि मल्टी-एटेंटिव कार्यों पर एलएलएम लेकिन कॉम्प्लेक्स कैलिब्रेशन की आवश्यकता, ग्राउंड-चांदी के पुरस्कारों का उपयोग करके पिछले उत्तरों की कमी। अन्य कार्य बाहरी उपकरणों का उपयोग करके आत्म-सुधार पर ध्यान केंद्रित करते हैं, जैसे कि आत्म-प्रतिबिंब के लिए एक प्रतिबिंब और वास्तविक समय की प्रतिक्रिया के लिए एक आलोचक। इन दृष्टिकोणों के विपरीत, प्रस्तावित विधि डिपिक आर 1 के एकल-टर्न-उत्तर काम को बहु-बैक में विस्तारित करती है, उत्तरों में सुधार करने और तर्क को बढ़ाने के लिए ऐतिहासिक गलतियों के लाभ देती है।
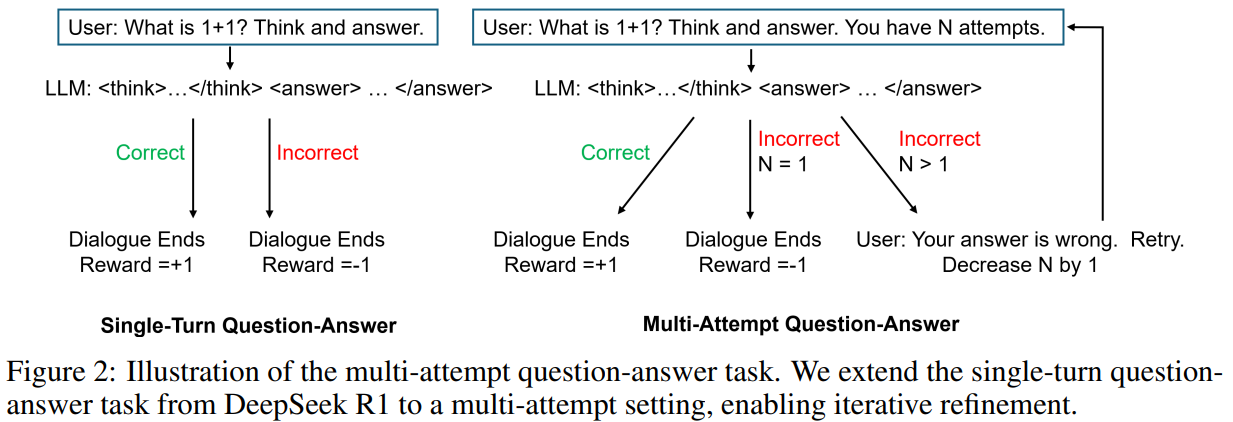
ड्यूलिट्रल और शंघाई एआई लैब शोधकर्ता एलएलएमएस में तर्क को बढ़ाने के लिए एक बहु-दृष्टिकोण आरएल दृष्टिकोण का परिचय देते हैं। एकल-टर्न कार्यों के विपरीत, यह विधि मॉडल को प्रतिक्रिया के साथ कई प्रयासों के माध्यम से उत्तर को सही करने की अनुमति देती है। प्रायोगिक परिणाम एकल-टर्न मॉडल में सीमांत लाभ की तुलना में गणितीय बेंचमार्क पर दो प्रयासों के साथ 45.6% से 52.5% की सटीकता में सुधार दिखाते हैं। मॉडल समीपस्थ नीति ऑप्टिमेशन ptimization (PPO) का उपयोग करके आत्म-सुधार सीखता है, जिससे उभरते तर्क की क्षमता होती है। यह मल्टी-एटमैट सेटिंग दोहरावदार शोधन की सुविधा प्रदान करती है, ईआर ग्रिप शिक्षा और समस्या को सुलझाने के कौशल को बढ़ावा देती है, जिससे यह पारंपरिक आरएलएचएफ का एक आशाजनक विकल्प बन जाता है और ठीक-ट्यूनिंग तकनीकों का अवलोकन किया जाता है।
एकल-अवधारणा के काम में, एलएलएम डेटासेट से नमूना किए गए प्रश्न की प्रतिक्रिया पैदा करता है, उत्तर की शुद्धता के आधार पर पुरस्कारों को अधिकतम करने के लिए अपनी नीति को बढ़ाता है। इसके विपरीत, एक बहु-टर्न दृष्टिकोण दोहराव शुद्धि की अनुमति देता है, जहां उत्तर बाद के संकेतों को प्रभावित करते हैं। प्रस्तावित बहु-सावधान कार्य एक निश्चित संख्या में प्रयासों का प्रतिनिधित्व करता है, यदि प्रारंभिक प्रतिक्रिया गलत है तो फिर से पूछता है। मॉडल को सही उत्तर के लिए +1, -0.5 का पुरस्कार मिलता है, झूठे लेकिन अच्छी तरह से अच्छी तरह से उत्तर, और -1 अन्यथा। यह दृष्टिकोण दंड के बिना प्रारंभिक प्रयासों में अनुसंधान को बढ़ावा देता है, सुदृढीकरण शिक्षा के माध्यम से तर्क को बढ़ाते हुए, इष्टतम ptimization के लिए पीपीओ का लाभ।
अध्ययन गणितीय प्रश्नों पर Qu = 1, λ = 0.99, और 0.01 के KL डायवर्सन गुणांक के साथ PPO का उपयोग करके ठीक-ट्यून करता है। प्रशिक्षण 1.28 वें नमूने का उत्पादन करते हुए 160 एपिसोड तक फैलता है। एक बहु-एटिट्यूड सेटिंग में, प्रयास को {1,…, से 5 से नमूना लिया गया है, जबकि बेसलाइन एक एकल-टर्न दृष्टिकोण का अनुसरण करती है। परिणाम बताते हैं कि बहु-परिवर्तनीय मॉडल उच्च पुरस्कार और थोड़ा बेहतर मूल्यांकन सटीकता प्राप्त करता है। विशेष रूप से, यह प्रभावी रूप से उत्तरों में सुधार करता है, जो कई प्रयासों में 45.58% से 53.82% तक सटीकता में सुधार करता है। यह अनुकूली तर्क क्षमता कोड पीढ़ी और समस्या को हल करने के क्षेत्रों में प्रभाव को बढ़ा सकता है।
अंत में, यह अध्ययन Dippic R1 के पूछताछ कार्य पर एक बहु-दृष्टिकोण तंत्र का निर्माण करता है। जबकि गणित बेंचमार्क पर प्रभाव का लाभ सामान्य है, दृष्टिकोण प्रतिक्रिया के आधार पर प्रतिक्रियाओं में सुधार करने के लिए मॉडल की क्षमता में काफी सुधार करता है। मॉडल, गलत उत्तरों पर दोहराने के लिए प्रशिक्षित, खोज दक्षता और आत्म-सुधार को बढ़ाता है। प्रायोगिक परिणाम बताते हैं कि दो प्रयासों के साथ सटीकता 45.6% से 52.5% तक सुधार करती है, जबकि एक एकल-टर्न मॉडल केवल थोड़ा बढ़ जाता है। भविष्य के कार्य एलएलएम क्षमताओं को बढ़ाने के लिए विस्तृत प्रतिक्रिया या सहायक कार्यों को शामिल करके आगे का पता लगा सकते हैं, जिससे यह दृष्टिकोण अनुकूली तर्क और जटिल समस्याओं के लिए मूल्यवान हो जाता है।
जाँच करना कागज़। इस शोध के लिए सभी श्रेय इस परियोजना के शोधकर्ताओं को जाते हैं। इसके अलावा, हमें फॉलो करने के लिए स्वतंत्र महसूस करें ट्विटर और हमसे जुड़ने के लिए मत भूलना 80K+ एमएल सबमिटेड।
। MEET PALLANT: व्यवहार दिशानिर्देशों और रनटाइम मॉनिटरिंग का उपयोग करके, अपने AI ग्राहक सेवा एजेंटों पर आवश्यक नियंत्रण और सटीकता प्रदान करने के लिए AI फ्रेमवर्क डेवलपर्स को प्रदान करने के लिए एक LLM-FIRST वार्तालाप किया गया है। 🔧 🔧 🎛 इसका उपयोग करना आसान है। और पायथन और टाइपस्क्रिप्ट में मूल ग्राहक एसडीके का उपयोग करके संचालित है।
मार्कटेकपोस्ट और आईआईटी मद्रास में एक परामर्श इंटर्न सना हसन, वास्तविक दुनिया की चुनौतियों को दूर करने के लिए प्रौद्योगिकी और एआई को लागू करने के बारे में उत्साहित हैं। व्यावहारिक समस्याओं को हल करने में अधिक रुचि के साथ, यह एआई और वास्तविक जीवन समाधानों के चौराहे के लिए एक नया परिप्रेक्ष्य लाता है।
पार्लेंट: LLMS (B ED) के साथ एक विश्वसनीय AI ग्राहक का सामना करना

