

नवीनतम अपडेट और प्रमुख एआई कवरेज पर विशिष्ट सामग्री के लिए हमारे दैनिक और साप्ताहिक समाचार पत्र में शामिल हों। और अधिक जानें
चेन-टू-एफ-थीटी (सीओटी) लॉजिक को काटने से पहले “थिंक” मॉडल में कामयाब रहा-यह फ्रंटियर लार्ज लैंग्वेज मॉडल (एलएलएम) की नवीनतम पे जेनरेशन का एक अभिन्न अंग बन गया है।
हालांकि, लॉजिक मॉडल की तर्क लागत जल्दी से ढेर कर सकती है क्योंकि मॉडल अधिक कोट टोकन का उत्पादन करते हैं। नए पेपर में, कार्नेगी मेलन विश्वविद्यालय के शोधकर्ताओं ने एलएलएम प्रशिक्षण तकनीक का प्रस्ताव किया है जो डेवलपर्स को सीओटी की लंबाई पर अधिक नियंत्रण देता है।
लंबाई -नियंत्रित नीति को ऑप्टिमेंट ptimization (LCPO), तकनीक, मॉडल के लिए सही उत्तर प्रदान करने वाला मॉडल के रूप में जाना जाता है, जबकि पूर्व निर्धारित टोकन बजट में अपने “विचारों” को भी रखते हुए। प्रयोगों से पता चलता है कि LCPO पर प्रशिक्षित मॉडल सटीकता और लागत के बीच एक सरल व्यापार प्रदान करते हैं और एक ही तर्क लंबाई पर बड़े मॉडलों को आश्चर्यचकित कर सकते हैं। LCPO एलएलएम के साथ बातचीत के प्रत्येक दौर में हजारों टोकन को बचाने के लिए एंटरप्राइज एप्लिकेशन में अनुमानों की लागत को कम करने में मदद कर सकता है।
LLM संचालन लंबे समय तक ले जाता है
OpenAI O1 और DEEPSIK-R1 जैसे लॉजिक मॉडल को टेस्ट-टाइम स्केलिंग का उपयोग करने और उत्तर बनाने से पहले कोट ट्रेस बनाने के लिए सुदृढीकरण लर्निंग (आरएल) द्वारा प्रशिक्षित किया जाता है। अनुभवजन्य साक्ष्य से पता चलता है कि जब मॉडल लंबे समय तक “सोचते हैं”, तो वे तर्क के कार्यों पर बेहतर प्रदर्शन करते हैं।
उदाहरण के लिए, R1 को शुरू में मानव-लेबल वाले उदाहरणों के बिना शुद्ध RL पर प्रशिक्षित किया गया था। एक अंतर्दृष्टि यह थी कि जैसे -जैसे मॉडल के प्रदर्शन में सुधार हुआ, इसने लंबे समय तक एक खाट ट्रेस का उत्पादन करना सीखा।
आम तौर पर, लंबी बिल्ली श्रृंखलाओं के परिणामस्वरूप अधिक सटीक प्रतिक्रिया होती है, वे पैमाने पर तर्क मॉडल को लागू करने के लिए एक बाधा भी बनाते हैं। परीक्षण-समय की गणना वर्तमान में बजट पर बहुत कम नियंत्रण है, और महत्वपूर्ण लाभ दिए बिना अनुक्रमों को आसानी से हजारों टोकन तक खींचा जा सकता है। तर्क श्रृंखलाओं की लंबाई को नियंत्रित करने के लिए कुछ प्रयास किए गए हैं, लेकिन वे आमतौर पर मॉडल के प्रदर्शन को कम करते हैं।
लंबाई -नियंत्रण नीति ऑप्टिमाइज़ेशन (LCPO) ने समझाया
क्लासिक आरएल विधि केवल सही प्रतिक्रिया प्राप्त करने के लिए एलएलएम को प्रशिक्षित करती है। LCPO दो प्रशिक्षण उद्देश्यों को प्रस्तुत करके इस पैटर्न को बदल देता है: 1) सही परिणाम प्राप्त करें और 2) कोट श्रृंखला को एक निश्चित टोकन लंबाई में रखें। इसलिए, यदि मॉडल सही प्रतिक्रिया का उत्पादन करता है, लेकिन बहुत सारे कैट टोकन का उत्पादन करता है, तो इसे एक जुर्माना प्राप्त होगा और इसे एक ही उत्तर तक पहुंचने वाले लॉजिक चेन के साथ आने के लिए मजबूर किया जाएगा, लेकिन एक छोटे टोकन बजट के साथ।
शोधकर्ता लिखते हैं, “LCPO- प्रशिक्षित मॉडल डेल्ट्स लंबाई बाधाओं को संतुष्ट करना सीखते हैं, जब हाथ से इंजीनियर हर्स्टिक्स पर भरोसा करने के बजाय तर्क को प्रदर्शित करता है।”
वे LCPs के दो स्वादों का सुझाव देते हैं: (1) LCPO-EXACT, जिसके लिए लक्ष्य लंबाई के बराबर की आवश्यकता होती है, और (2) LCPO-MAX, जो आउटपुट लक्ष्य लंबाई से अधिक नहीं है।
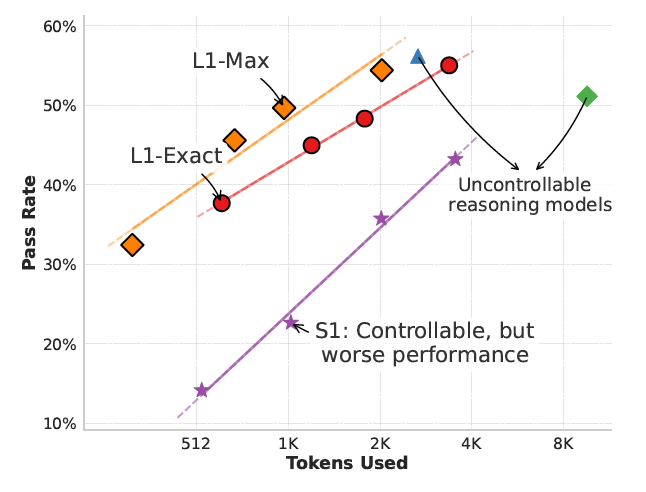
प्रौद्योगिकी का परीक्षण करने के लिए, शोधकर्ताओं ने एल 1-मैक्स और एल 1-एक्सैक्ट मॉडल बनाने के लिए दो प्रस्तावित एलसीपीओ योजनाओं पर 1.5 बी-पैरामीटर लॉजिक मॉडल (क्वीन-डिस्टिल्ड-आर 1.5 बी) को ठीक किया। प्रशिक्षण विभिन्न और सत्यापित परिणामों के साथ गणितीय समस्याओं पर आधारित था। हालांकि, गणित की समस्याओं के साथ-साथ मापन बड़े मल्टीटास्क लैंग्वेज अंडरस्टैंडिंग (MMLU) तकनीक और ग्रेजुएट-लेवल Google- प्रूफ Q & A बेंचमार्क (GPQA) जैसे मापन-ऑफ-डिस्ट्रिब्यूशन कार्यों का मूल्यांकन।
उनके निष्कर्षों से पता चलता है कि L1 मॉडल टोकन बजट और तर्क प्रदर्शन को सही ढंग से समायोजित कर सकते हैं, आसानी से एक मॉडल के साथ अधिक सटीक तर्क के बीच एक बाधा, कुशल तर्क और लंबे समय तक एक बाधा के साथ पूछ सकते हैं। महत्वपूर्ण रूप से, कुछ कार्यों पर, L1 मॉडल निचले टोकन बजट पर मूल लॉजिक मॉडल के प्रभाव को पुन: पेश कर सकते हैं।

S1 की तुलना में – एकमात्र अन्य विधि जो COT – L1 मॉडल की लंबाई में बाधा डालती है, विभिन्न टोकन बजट पर 150% प्रभाव का लाभ दिखाती है।
शोधकर्ता लिखते हैं, “यह महत्वपूर्ण अंतर दो प्रमुख कारकों के लिए जिम्मेदार है।” “(1) L1 तर्क प्रक्रिया को बाधित किए बिना एक स्पष्ट लंबाई अवरोध में फिट होने के लिए अपना हिस्सा सूट करता है, जबकि S1 अक्सर मध्य-रेजेन को काटता है; और (2) L1 स्पष्ट रूप से विभिन्न लंबाई की उच्च-गुणवत्ता वाले लॉजिक चेन के उत्पादन में प्रशिक्षित है, प्रभावी रूप से लंबी श्रृंखलाओं से छोटी अवधि तक तर्क पैटर्न को परेशान करता है। “
L1 GPT -4O द्वारा एक ही पे -गेंशन लंबाई पर अपने गैर -कॉन्सेप्टिंग समकक्ष को 5% और 2% तक धकेलता है। शोधकर्ता लिखते हैं, “हमारे सबसे अच्छे जे ज्ञान के अनुसार, यह पहला प्रदर्शन है कि 1.5B मॉडल एक ही पे -गर्जन लंबाई का उपयोग करने के बावजूद GPT -4O जैसे फ्रंटियर मॉडल को बेहतर बना सकता है।”
दिलचस्प बात यह है कि मॉडल की सीओटी से पता चलता है कि यह अपने टोकन बजट के आधार पर अपनी तर्क प्रक्रिया को समायोजित करना सीखता है। उदाहरण के लिए, एक लंबे बजट पर, मॉडल को आत्म-सुधार और जांच (यानी, “लेकिन” और “प्रतीक्षा”) और निष्कर्ष (“सो” और “सो”) से जुड़े टोकन का उत्पादन करने की संभावना है।

मानक गणित लॉजिक सेटिंग में बेहतर लंबाई नियंत्रण के अलावा, L1 मॉडल को GPQA और MMLU सहित बाहर किए गए कार्यों में आश्चर्यजनक रूप से सामान्य किया जाता है।
उन मॉडलों पर अनुसंधान की यह नई लाइन जो उनके तर्क बजट को समायोजित कर सकती है, वास्तविक दुनिया के अनुप्रयोगों के लिए महत्वपूर्ण उपयोग हो सकती है, जो उद्यमशीलता की लागत के बिना तर्क मॉडल को स्केल करने की क्षमता देता है। यह बड़े, अधिक महंगे मॉडल को तैनात करने के लिए एक शक्तिशाली विकल्प है और वास्तविक दुनिया के आवेदन के लिए एआई को अधिक आर्थिक रूप से व्यवहार्य बनाने के लिए एक उच्च-मात्रा एक महत्वपूर्ण कारक हो सकता है।
शोधकर्ताओं ने LCPO कोड और L1 मॉडल के लिए वजन खोला है।



