


बड़े भाषा मॉडल डेलो (एलएलएमएस) ने प्राकृतिक भाषा की समझ और जटिल तर्क सहित विभिन्न कार्यों पर अपने सर्वश्रेष्ठ प्रदर्शन के साथ कृत्रिम बुद्धिमत्ता को बदल दिया है। हालांकि, इन मॉडलों को नए कार्यों में स्वीकार करना एक महत्वपूर्ण चुनौती है, क्योंकि पारंपरिक फाइन-ट्यूनिंग विधियों में बड़े लेबल वाले डेटासेट और भारी गिनती संसाधन शामिल हैं। कई एलएलएमएस को जोड़ने के मौजूदा तरीकों में आवश्यक राहत की कमी है और नए कार्यों में सामान्यीकरण में चुनौतियों का सामना करना पड़ रहा है। इसके अलावा, ग्रेड आधारित इष्टतम सीमा निर्भरता दक्षता और स्केलेबिलिटी को सीमित करता है, जिससे वास्तविक समय अनुकूलन असंभव हो जाता है। इसलिए, एक अधिक प्रभावी दृष्टिकोण की तत्काल आवश्यकता है जो LLM को गतिशील रूप से अनुकूलित करने की अनुमति देता है, भारी गणना की कीमतों का भुगतान किए बिना प्रदर्शन को अनुकूलित करने और प्रदर्शन में सुधार करने के लिए न्यूनतम डेटा की आवश्यकता होती है।
एलएलएम अनुकूलन को बढ़ाने के लिए कई तरीकों का सुझाव दिया गया है, हालांकि प्रत्येक में आवश्यक कमियां हैं। विशेषज्ञ संलयन पूर्वनिर्धारित नियमों के अनुसार औसत से अपने मापदंडों को औसत करके ठीक-धुन मॉडल का विलय करता है, हालांकि विधि को गतिशील रूप से एक विशिष्ट कार्य के लिए अनुकूलित नहीं किया जा सकता है। अन्य तरीके, जैसे कि लोराहब और मॉडल स्वर्म, एडेप्टिव मॉडल को संयोजित करने के लिए आनुवंशिक प्रोग्रामिंग या कण स्वर्म स्विम ऑप्टिमाइज़ेशन जैसे विकास एल्गोरिदम का उपयोग करते हैं। फिर भी, उन्हें लेबल किए गए अनुकूलन डेटा की आवश्यकता होती है और कई कार्यों में स्केलिंग करते समय प्रदर्शन कम हो जाता है। आयाम को विलय करने के तरीके जैसे कि साहस, रिश्ते और एलएलएम के पैक संरेखित करते हैं और विभिन्न मॉडलों से विलय करते हैं, हालांकि, मांगों को गतिशील रूप से बदलने के लिए अनुकूलित नहीं किया जा सकता है। इन विधियों की साझा कमियों में उच्च गणना जटिलता, निश्चित अनुकूलन विधियों और शून्य-शॉट टीएस सेटिंग्स में खराब सामान्यीकरण क्षमता है। ये कमियां एक अधिक परिष्कृत समाधान की आवश्यकता पर जोर देती हैं जो व्यापक वसूली की आवश्यकता के बिना कार्यों के लिए विकसित और अनुकूलन जारी रख सकते हैं।
पूर्वोत्तर विश्वविद्यालय और शंघाई आर्टिफिशियल इंटेलिजेंस लेबोरेटरी विश्वविद्यालय के शोधकर्ताओं ने जीनोम (मॉडल इवोल्यूशन के लिए आनुवंशिक इष्टतम ptimization) का प्रस्ताव दिया, एक जनसंख्या -आधारित विकास संरचना जिसे एलएलएम अनुकूलन को बढ़ाने के लिए डिज़ाइन किया गया है। मॉडल के विकासशील मॉडल के लिए दृष्टिकोण आनुवंशिकी का उपयोग करता है, अर्थात्, क्रॉसओवर, परिवर्तन, चयन और उत्तराधिकार के तरीके। ग्रेड डल आधारित शिक्षा के आधार पर पारंपरिक फाइन-ट्यूनिंग के विपरीत, जीनोम बिखरे हुए डेटा के तहत सफल विकास को सक्षम बनाता है। क्रॉसओवर बेहतर क्षमताओं के साथ संतानों को बनाने के लिए उच्च -प्रदर्शन करने वाले मॉडल की योग्यता की अनुमति देता है, जबकि परिवर्तन नई क्षमताओं को खोजने के लिए यादृच्छिकता को जोड़ देगा। विकल्प केवल बहुत कुशल मॉडल बनाए रखता है और सबप्टिमल वाले को अस्वीकार करता है, और उत्तराधिकार पिछले संस्करणों की शक्ति और कमजोरियों को प्राप्त करने के लिए नए विकसित मॉडल को जूनोवलेज के हस्तांतरण की अनुमति देता है। एक प्रकार का जीनोम+ एक अटैचमेंट मैकेनिज्म जोड़ता है जो ताकत और सटीकता में सुधार करने के लिए शीर्ष प्रदर्शन करने वाले मॉडल के पूर्वानुमानों को जोड़ता है। ये नवाचार LLM को पारंपरिक मॉडल अनुकूलन दृष्टिकोणों के लिए एक संशोधित और स्केलेबल विकल्प की पेशकश करते समय नए कार्यों के लिए जल्दी से अनुकूलित करने की अनुमति देते हैं, कम्प्यूटेशनल संसाधनों को कम करते हैं।
इवोल्यूशनरी मॉडल डेल को Gemma-2-2B-II-SEWED LLM आबादी द्वारा लागू किया जाता है, Tulu-V2-SFT डेटासेट का उपयोग करके 10 डोमेन पर धुनें ठीक हैं। विकासवादी संचालन को बार-बार वेतन पीढ़ियों पर लागू किया जाता है, फाइन-ट्यूनिंग मॉडल आयाम, फिटनेस फ़ंक्शन का उपयोग करते हुए, उन्हें ऑप्टिमेट के साथ ptimizing द्वारा सत्यापन सटीकता। सिस्टम 10 से 40 मॉडलों के बीच आबादी के आकार के साथ चलता है, जिसमें 30% की क्रॉसओवर दर और 20% का परिवर्तन होता है। सटीकता, सटीक मैच, एफ 1-स्कोर और ब्लू स्कोर का उपयोग बहुभाषी कार्यों के लिए एक मूल्यांकन मैट्रिक्स के रूप में किया जाता है। दृष्टिकोण गणनात्मक रूप से कुशल है और इसे एकल RTX 4090 GPU पर चलाया जाता है, जिससे यह पारंपरिक फाइन-ट्यूनिंग दृष्टिकोणों के लिए एक व्यावहारिक और व्यावहारिक विकल्प बन जाता है।


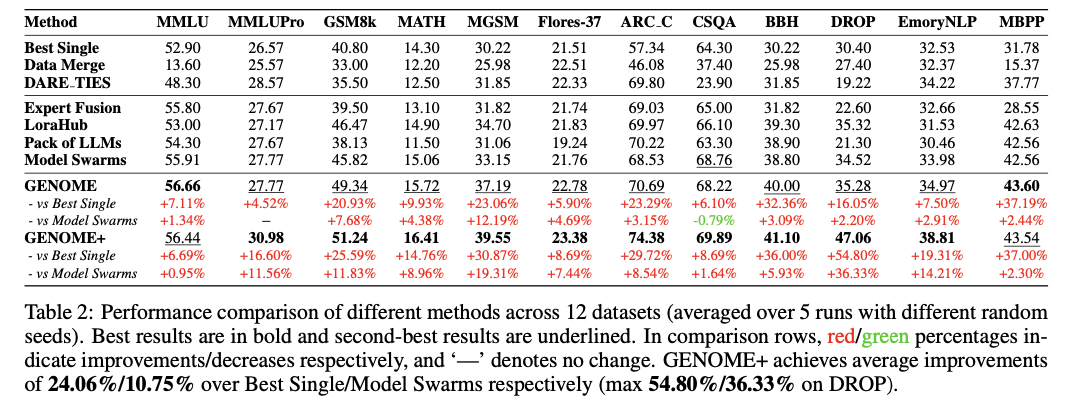
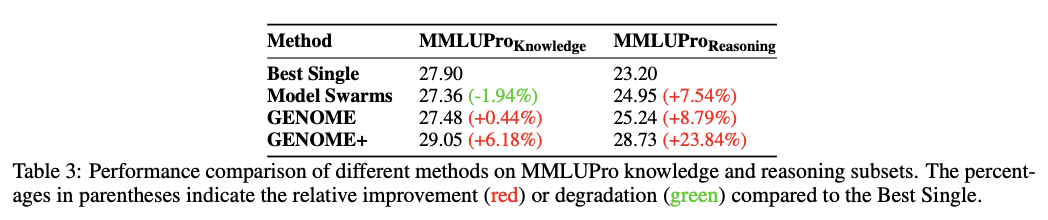
बड़े -स्केल मूल्यांकन पुष्टि करता है कि यह दृष्टिकोण उन्नत सटीकता, तर्क और स्केलिंग के संदर्भ में कई बेंचमार्क पर आधुनिक मॉडल अनुकूलन और संयोजन विधियों से अधिक है। सिस्टम शीर्ष प्रदर्शन करने वाले एकल विशेषज्ञ मॉडल और औसतन 24.06% लाभ 10.75% पर प्राप्त करता है, जिसमें स्रोत-बढ़ते तर्क पर एक महत्वपूर्ण लाभ होता है। अन्य अनुकूली तरीकों के विपरीत, जो कई कार्यों का सामना करते समय विकलांग होते हैं, यह विकासवादी दृष्टिकोण डोमेन की विस्तृत श्रृंखला पर एक निरंतर प्रभाव दिखाता है। इसके अलावा, यह एक मजबूत शून्य-शॉट टिंग सामान्यीकरण को प्राप्त करता है, अतिरिक्त प्रशिक्षण डेटा की आवश्यकता के बिना सीखे गए अभ्यावेदन को सफलतापूर्वक स्थानांतरित करता है। स्केलेबिलिटी प्रयोग इस बात की पुष्टि करते हैं कि आबादी के आकार में 10 से 40 मॉडल बढ़ाने से प्रदर्शन में सुधार होता है। एबेलिकेशन अध्ययन प्रत्येक विकास प्रक्रिया के महत्व की पुष्टि करता है, चयन और कनेक्शन के तरीके समग्र प्रभावशीलता में महत्वपूर्ण भूमिका निभाते हैं।
LLMS में जनसंख्या -आधारित विकास को लागू करने से, यह पेपर एक क्रमिक, अनुकूली और स्केलेबल इष्टतम ptimization विधि प्रस्तुत करता है जो कम डेटा की स्थितियों में निरंतर सुधार की अनुमति देता है। आनुवंशिक गणितीय नियमों के सिद्धांतों के बाद, विधि मॉडल को गतिशील रूप से विकसित करने की अनुमति देती है, पारंपरिक अनुकूलन विधियों की तुलना में बेहतर प्रदर्शन करती है, और उपन्यास के कार्यों को सामान्य करती है। वर्तमान हार्डवेयर पर लागत प्रभावी कार्यान्वयन में, जीनोम+ पारंपरिक फाइन-ट्यूनिंग और मॉडल फ्यूजन विधियों के लिए आर्थिक और वास्तविक दुनिया के समाधान प्रस्तुत करता है, जिससे एआई सिस्टम को लगातार सुधार और अनुकूलित करने में सक्षम बनाता है।
जाँच करना कागज़। इस शोध के लिए सभी श्रेय इस परियोजना के शोधकर्ताओं को जाते हैं। इसके अलावा, हमें फॉलो करने के लिए स्वतंत्र महसूस करें ट्विटर और हमसे जुड़ने के लिए मत भूलना 80K+ एमएल सबमिटेड।
। MEET PALLANT: व्यवहार दिशानिर्देशों और रनटाइम मॉनिटरिंग का उपयोग करके, अपने AI ग्राहक सेवा एजेंटों पर आवश्यक नियंत्रण और सटीकता प्रदान करने के लिए AI फ्रेमवर्क डेवलपर्स को प्रदान करने के लिए एक LLM-FIRST वार्तालाप किया गया है। 🔧 🔧 🎛 इसका उपयोग करना आसान है। और पायथन और टाइपस्क्रिप्ट में मूल ग्राहक एसडीके का उपयोग करके संचालित है।
Aswin AK MaviyechPost में एक परामर्श इंटर्न है। उन्हें खड़गपुर में भारतीय प्रौद्योगिकी में दोहरी डिग्री मिल रही है। यह डेटा अभिव्यक्तियों और पंखों और मशीन लर्निंग के बारे में उत्साही है, एक मजबूत शैक्षणिक पृष्ठभूमि और वास्तविक जीवन क्रॉस-डॉमन चुनौतियों को हल करने में अनुभव लाता है।
पार्लेंट: LLMS (B ED) के साथ एक विश्वसनीय AI ग्राहक का सामना करना

