

नवीनतम अपडेट और प्रमुख एआई कवरेज पर विशिष्ट सामग्री के लिए हमारे दैनिक और साप्ताहिक समाचार पत्र में शामिल हों। और अधिक जानें
शंघाई एआई प्रयोगशाला के एक नए अध्ययन के अनुसार, मॉडल के बहुत छोटे मॉडल (एसएलएम) तर्क कार्यों में अग्रणी बड़े -लैंगुएज मॉडल डेल (एलएलएम) को बेहतर बना सकते हैं। लेखक बताते हैं कि उपयुक्त उपकरण और परीक्षण-समय स्केलिंग तकनीकों के साथ, 1 बिलियन आयामों के साथ एसएलएम जटिल गणित के बेंचमार्क पर 405 बी एलएलएम तक आगे बढ़ सकते हैं।
जटिल तर्क कार्यों में एसएलएम को तैनात करने की क्षमता बहुत उपयोगी हो सकती है क्योंकि उद्यम विभिन्न वातावरणों और अनुप्रयोगों में इन नए मॉडलों का उपयोग करने के लिए नए तरीकों की तलाश कर रहा है।
परीक्षण-समय स्केलिंग समझाया
टेस्ट-टाइम स्केलिंग (टीटीएस) विभिन्न कार्यों पर उनके प्रदर्शन में सुधार करने के लिए अनुमान के दौरान एलएलएमएस अतिरिक्त गणना चुप्पी प्रदान करने की प्रक्रिया है। अग्रणी लॉजिक मॉडल, जैसे कि Openai O1 और DEEPSK-R1, “आंतरिक TTS” का उपयोग करते हैं, जिसका अर्थ है कि वे चेन-थ एफ-थॉट (COT) टोकन के एक लंबे तार को “प्राप्त” करने के लिए प्रशिक्षित करते हैं।
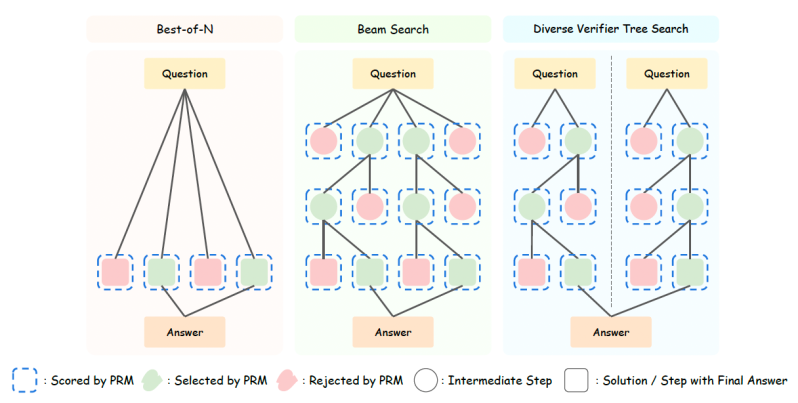
वैकल्पिक दृष्टिकोण “बाहरी टीटीएस” है, जहां बाहरी सहायता को मॉडल प्रदर्शन (नाम इंगित करता है) के साथ बढ़ाया जाता है। बाहरी टीटीएस बेहतर ट्यूनिंग के बिना तर्क कार्यों के लिए निकास मॉडल को फिर से प्रस्तुत करने के लिए एकदम सही है। बाहरी टीटीएस सेटअप आमतौर पर एक “नीति मॉडल” से बना होता है, जो कि मुख्य एलएलएम है जो उत्तर का उत्पादन करता है, और एक प्रक्रिया इनाम मॉडल (पीआरएम) जो नीति मॉडल के प्रतिवादी का मूल्यांकन करता है। इन दोनों घटकों को एक नमूना या खोज विधि द्वारा एक साथ जोड़ा जाता है।
सबसे आसान सेटअप “बेस्ट-एफ-एन” है, जहां पॉलिसी मॉडल कई उत्तरों का उत्पादन करता है और पीआरएम अंतिम प्रतिक्रिया लिखने के लिए एक या अधिक सर्वश्रेष्ठ उत्तर चुनता है। अधिक उन्नत बाहरी टीटीएस विधियाँ खोज का उपयोग करती हैं। “बीम खोज” में, मॉडल उत्तर को कई चरणों में तोड़ देता है।
प्रत्येक चरण के लिए, यह कई उत्तर नमूने देता है और उन्हें पीआरएम द्वारा चलाता है। वह तब एक या अधिक उपयुक्त उम्मीदवारों का चयन करता है और उत्तर का अगला कदम बनाता है। और, “अलग -अलग सत्यापित ट्री सर्च” (डीवीटी) में, मॉडल अंतिम उत्तर में संश्लेषित करने से पहले उम्मीदवारों के उत्तरों के अधिक विविध सेट बनाने के लिए उत्तर की कई शाखाओं का उत्पादन करता है।

सही स्केलिंग रणनीति क्या है?
सही टीटीएस रणनीति चुनना कई कारकों पर निर्भर करता है। अध्ययन लेखकों ने एक व्यवस्थित जांच की है कि विभिन्न नीतियों की दक्षता डेलो और पीआरएमएस टीटीएस विधियों को कैसे प्रभावित करती है।
उनके निष्कर्ष बताते हैं कि कार्यक्षमता काफी हद तक नीति और पीआरएम मॉडल पर आधारित है। उदाहरण के लिए, छोटे नीति मॉडल के लिए, खोज-आधारित तरीके सबसे अच्छे हैं। हालांकि, बड़े नीति मॉडल डेलो के लिए, सबसे अच्छा-एफ-एन अधिक प्रभावी है क्योंकि तर्क क्षमताएं मॉडल में बेहतर हैं और उनके तर्क के हर चरण का परीक्षण करने के लिए कोई इनाम मॉडल की आवश्यकता नहीं है।
उनके निष्कर्ष यह भी बताते हैं कि उपयुक्त टीटीएस रणनीति समस्या की समस्या पर निर्भर करती है। उदाहरण के लिए, 7 बी से कम आयामों वाले छोटे नीति मॉडल के लिए, सर्वश्रेष्ठ-एफ-एन सरल समस्याओं के लिए बेहतर काम करता है, जबकि बीम खोज सख्त समस्याओं के लिए बेहतर काम करता है। पॉलिसी मॉडल डेलो जिसके लिए 7B और 32B पैरामीटर हैं, विभिन्न ट्री सर्च आसान और मध्यम समस्याओं के लिए अच्छा प्रदर्शन करता है, और बीम खोज सख्त समस्याओं के लिए सबसे अच्छा काम करता है। लेकिन बड़े पॉलिसी मॉडल डेलो (72 बी पैरामीटर और अधिक) के लिए, सबसे अच्छा-एन मुसीबत के सभी स्तर के लिए सबसे अच्छा तरीका है।
क्यों छोटे मॉडल बड़े मॉडल को हरा सकते हैं

इन निष्कर्षों के आधार पर, डेवलपर्स एक कंप्यूटर-बेस्ट टीटीएस रणनीति बना सकते हैं जो तर्क समस्याओं को हल करने के लिए गणना बजट का सबसे अच्छा उपयोग करने के लिए पॉलिसी मॉडल, पीआरएम और समस्या कठिनाई पर विचार करता है।
उदाहरण के लिए, शोधकर्ताओं ने पाया कि गणित -500 और एआईएम 24 पर, लालमा -3.1-405 बी पर दो जटिल गणित के बेंचमार्क का नेतृत्व करते हुए एक गणना -टीटीएमएएल टीटीएस रणनीति के साथ एक लालमा और एआईएम 24 पर। इससे पता चलता है कि SLM कंप्यूटर-टाइम Ptimal TTS रणनीति का उपयोग करते समय एक मॉडल को अग्रेषित कर सकता है जो 135x बड़ा है।
दूसरे में एक ही रणनीति का उपयोग करते हुए, Math-500 और AIM 24 पर Dippic-R1, O1-View और O1-Mini का 1.5B डिस्टिल्ड संस्करण।
प्रशिक्षण और अनुमान गणना बजट दोनों के लिए गणना करते समय, निष्कर्ष बताते हैं कि कंप्यूटिंग-बेस्ट स्केलिंग रणनीति के साथ, SLM 100-1000X बड़े मॉडल को कम फ्लॉप के साथ स्थानांतरित कर सकता है।
शोधकर्ताओं के परिणाम बताते हैं कि गणना-सर्वश्रेष्ठ टीटीएस का तर्क भाषा मॉडल द्वारा काफी बढ़ाया जाता है। हालांकि, जैसे -जैसे पॉलिसी मॉडल डेल बढ़ता है, टीटीएस में सुधार धीरे -धीरे कम हो जाता है।
“यह इंगित करता है कि टीटीएस की प्रभावशीलता सीधे नीति मॉडल के तर्क से संबंधित है,” शोधकर्ता लिखते हैं। “विशेष रूप से, कमजोर तर्क क्षमता वाले मॉडल के लिए, परीक्षण-समय की गिनती में स्केलिंग से महत्वपूर्ण सुधार होता है, जबकि मजबूत तर्क क्षमता वाले मॉडल के लिए, लाभ सीमित हैं।”
अध्ययन यह मानता है कि गणना-सर्वश्रेष्ठ परीक्षण-समय स्केलिंग विधियों को लागू करते समय SLM बड़े मॉडलों की तुलना में बेहतर काम कर सकता है। जबकि यह अध्ययन गणित के बेंचमार्क पर केंद्रित है, शोधकर्ताओं ने अपने अध्ययन को अन्य तर्क जैसे कोडिंग और रसायन विज्ञान में विस्तारित करने की योजना बनाई है।



