

मस्तिष्क में भाषा प्रक्रिया स्वाभाविक रूप से जटिल, बहुआयामी और प्रासंगिक प्रकृति के कारण चुनौती का प्रतिनिधित्व करती है। मनोचिकित्सा .no ने डोमेन के लिए अच्छी तरह से परिभाषित प्रतीकात्मक विशेषताएं और प्रक्रियाएं बनाने की कोशिश की है, जैसे कि वाक्यविन्यास संरचनाओं के लिए भाषण विश्लेषण और भाग-परीक्षण इकाइयाँ। कुछ क्रॉस-डॉवरमैन इंटरैक्शन को स्वीकार करने के बावजूद, अनुसंधान द्वारा नियंत्रित प्रयोगात्मक जोड़तोड़ अलगाव में प्रत्येक भाषाई उप-क्षेत्र को मॉडलिंग करने पर केंद्रित है। यह विभाजन और विस्फोट रणनीति की सीमाओं को दर्शाता है, क्योंकि प्राकृतिक भाषा प्रक्रिया और औपचारिक छद्म मनोविज्ञान के बीच महत्वपूर्ण अंतराल सामने आए हैं। ये मॉडल और सिद्धांत सूक्ष्म, गैर-रैखिक, संदर्भ-आधारित बातचीत को पकड़ने के लिए संघर्ष करते हैं और भाषाई विश्लेषण से घिरे होते हैं।
एलएलएम में हाल की प्रगति ने भाषा प्रक्रिया, सारांश और वेतन पीढ़ी में नाटकीय रूप से सुधार किया है। ये मॉडल सिंथेटिक, सिमेंटिक और लिखित पाठ व्यावहारिक गुणों के प्रबंधन और ध्वनिक रिकॉर्डिंग के साथ भाषण को पहचानने में उत्कृष्ट हैं। मल्टीमॉडल, एंड-टू-एंड मॉडल प्राकृतिक संचार के दौरान निरंतर श्रवण इनपुट और शब्द-स्तरीय भाषाई आयामों में निरंतर श्रवण इनपुट को परिवर्तित करने के लिए एक समेकित संरचना प्रदान करके पाठ-केवल मॉडल पर महत्वपूर्ण सैद्धांतिक प्रगति का प्रतिनिधित्व करते हैं। पारंपरिक दृष्टिकोणों के विपरीत, ये गहरी पांड ध्वनिक-से-स्पिट-टू-लिंगुइक मॉडल बहुआयामी वैश्चरियल अभ्यावेदन की ओर पलायन करते हैं, जहां भाषण और भाषा के सभी तत्व लगातार सरल कंप्यूटिंग इकाइयों की आबादी में अंतर्निहित होते हैं, जो प्रत्यक्ष वस्तुओं को ptiming करके।
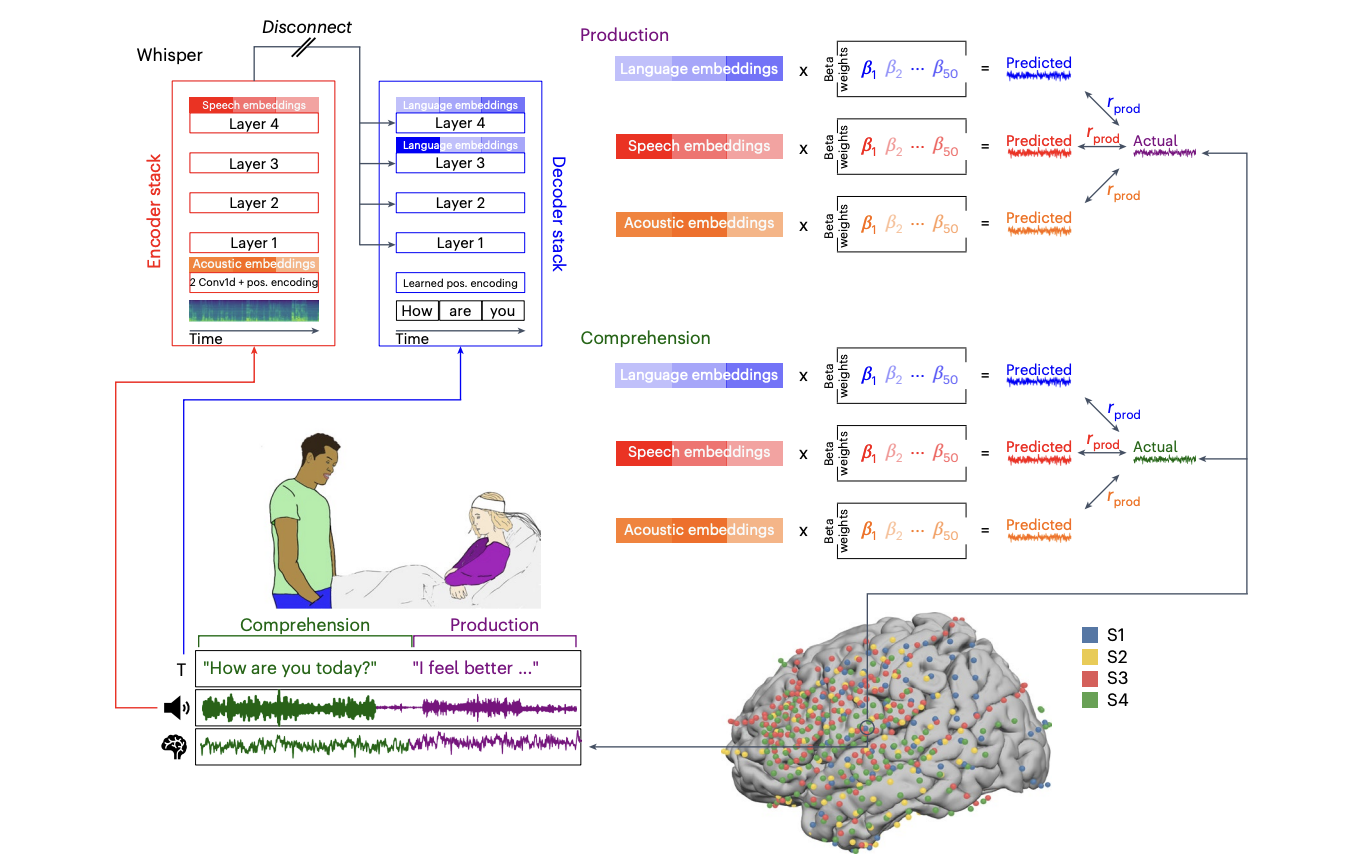
हिब्रू विश्वविद्यालय, Google अनुसंधान, प्रिंसटन विश्वविद्यालय, मास्टरीसिटी यूनिवर्सिटी, मैसाचुसेट्स जनरल हॉस्पिटल और हार्वर्ड मेडिकल स्कूल, न्यूयॉर्क यूनिवर्सिटी स्कूल मेडिसिन फॉर मेडिसिन, और हार्वर्ड यूनिवर्सिटी के शोधकर्ताओं ने एकजुट होकर समेकित किया है, और मानव मन के तंत्रिका समर्थन की जांच के लिए एक संकीर्ण आधार है। उन्होंने प्राकृतिक भाषण के 100 घंटे के उत्पादन में तंत्रिका संकेतों को रिकॉर्ड करने के लिए इलेक्ट्रोकोर्टिकोग्राफी का उपयोग किया, और खुले अंत में वास्तविक -जीवन वार्तालापों में लगे प्रतिभागियों के रूप में विस्तृत किया। टीम ने विभिन्न एम्बेडिंग जैसे कि मल्टीमॉडल स्पीच-टू-टेक्स्ट मॉडल जैसे व्हिस्पर नामक, जैसे कि निम्न-स्तरीय ध्वनिक, मध्य-स्तरीय भाषण और संदर्भित शब्द एम्बेडिंग। उनका मॉडल पिछले अदृश्य संचार के घंटों के भीतर भाषा प्रसंस्करण पदानुक्रम के हर स्तर पर तंत्रिका गतिविधि की भविष्यवाणी करता है।
ध्वनिक-से-स्पीड-टू-लिंग मॉडल के दैनिक संचार के दौरान कानाफूसी मॉडल और तंत्रिका गतिविधि की भविष्यवाणी करने के लिए जांच की जाती है। प्रत्येक शब्द रोगियों या तीन प्रकार के एम्बेडिंग की सूची की सूची से बोलता है: श्रवण इनपुट परत से ध्वनिक एम्बेडिंग, अंतिम भाषण एनकोडर स्तर से भाषण एम्बेडिंग और डिकोडर की अंतिम परतों से भाषा एम्बेडिंग। प्रत्येक एम्बेडिंग प्रकार के लिए, इलेक्ट्रोड -वाइज एन्कोडिंग मॉडल भाषण के उत्पादन और समझ के दौरान तंत्रिका गतिविधि के एम्बेडिंग को मैप करने के लिए बनाए जाते हैं। एन्कोडिंग मॉडल मानव मस्तिष्क गतिविधि और मॉडल के आंतरिक जनसंख्या कोड के बीच एक महत्वपूर्ण विन्यास दिखाते हैं, संचार डेटा में सैकड़ों हजारों शब्दों में तंत्रिका प्रतिक्रियाओं की सटीक भविष्यवाणी करते हैं।
कानाफूसी मॉडल की ध्वनि, भाषण और भाषा एम्बेडिंग, कॉर्टिकल भाषा नेटवर्क में भाषण के निर्माण और समझ के दौरान सैकड़ों हजारों शब्दों में तंत्रिका गतिविधि के लिए असाधारण भविष्यवाणी की सटीकता दिखाती है। भाषण के उत्पादन के दौरान, एक पदानुक्रमित प्रसंस्करण पाया जाता है, जहां आर्टिकुलेटरी एरिया (PREG, POSTSG, STG) भाषण को एंबेडिंग द्वारा बेहतर भविष्यवाणी की जाती है, जबकि उच्च-स्तरीय भाषा क्षेत्रों (IFG, PMTG, AG) को भाषा एम्बेडिंग के साथ आयोजित किया जाता है। एन्कोडिंग मॉडल अस्थायी विशिष्टता दिखाते हैं, उत्पादन की शुरुआत से पहले 300 मिमी से अधिक शब्द की शुरुआत के बाद और समझ के दौरान 300 मिमी की शुरुआत, भाषण एम्बेडिंग ऑर्डर राइडर भाषा के क्षेत्रों में बेहतर गतिविधि की भविष्यवाणी कर रहे हैं।
सारांश में, ध्वनिक-से-स्पिट-टू-लैंग्वेज मॉडल प्राकृतिक भाषा प्रक्रिया के तंत्रिका आधार की जांच के लिए एक एकीकृत गणना संरचना प्रदान करता है। यह एकीकृत दृष्टिकोण सांख्यिकीय शिक्षा और उच्च-आयामी एम्बेडिंग रिक्त स्थान के आधार पर गैर-खुलासा मॉडल की ओर एक उदाहरण है। जैसा कि ये मॉडल प्राकृतिक भाषण को बेहतर ढंग से संसाधित करने के लिए विकसित होते हैं, ओजीएन प्रक्रियाओं के साथ संरेखण समान रूप से सुधार कर सकता है। कुछ उन्नत मॉडल, जैसे कि GPT-4O, में भाषण और पाठ के साथ-साथ दृश्य मोडुलिटी शामिल है, जबकि अन्य मानव भाषण के निर्माण की नकल करने वाले सन्निहित आर्टिक्यूलेशन सिस्टम को एकीकृत करते हैं। इन मॉडलों का तेजी से सुधार एक एकीकृत भाषाई पैटर्न में बदलाव का समर्थन करता है जो भाषा अधिग्रहण में उपभोग-आधारित सांख्यिकीय शिक्षा की भूमिका पर जोर देता है क्योंकि यह वास्तविक जीवन संदर्भों में भौतिक है।
जाँच करना पेपर और गूगल ब्लॉग। इस शोध के लिए सभी श्रेय इस परियोजना के शोधकर्ताओं को जाते हैं। इसके अलावा, हमें फॉलो करने के लिए स्वतंत्र महसूस करें ट्विटर और हमसे जुड़ने के लिए मत भूलना 85 k+ ml सबमिटेड।

साजद अंसारी आईआईटी खड़गपुर से अंतिम वर्ष की स्नातक हैं। एक तकनीकी उत्साही के रूप में, यह एआई तकनीकों और उनके वास्तविक दुनिया के प्रभावों के प्रभाव पर ध्यान केंद्रित करके एआई के व्यावहारिक अनुप्रयोगों पर विचार करता है। इसका उद्देश्य स्पष्ट रूप से और सुलभ जटिल एआई अवधारणाओं का है।


