
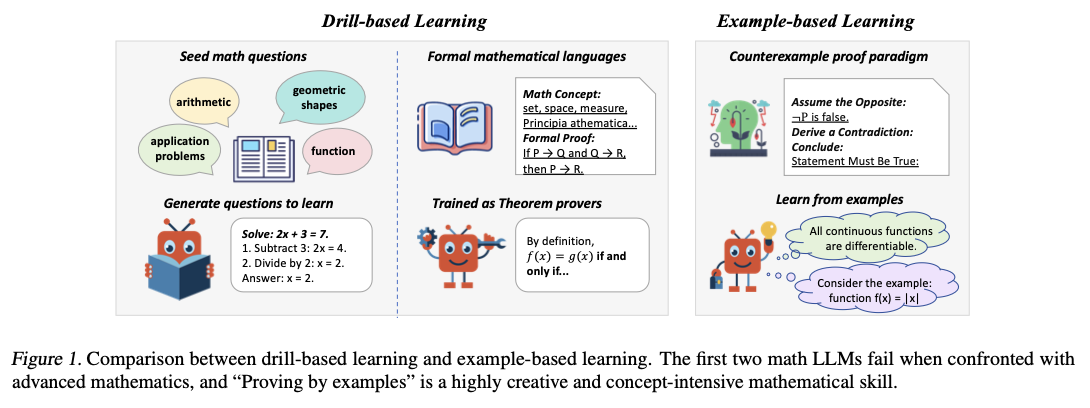

गणितीय बड़ी भाषा के मॉडल डेलो (एलएलएम) ने समस्या को हल करने के लिए मजबूत क्षमताओं को दिखाया है, लेकिन उनकी तर्क क्षमता को अक्सर एक सच्ची वैचारिक समझ के बजाय पैटर्न की मान्यता द्वारा अवरुद्ध किया जाता है। वर्तमान मॉडल उनके प्रशिक्षण के हिस्से के रूप में समान साक्ष्य के संपर्क पर आधारित हैं, नई गणितीय समस्याओं के लिए उनके एक्सट्रपलेशन को सीमित करते हैं। यह बाधा एलएलएम को उन्नत गणितीय तर्क को रोकने से रोकती है, विशेष रूप से निकट संबंधी गणितीय अवधारणाओं के बीच अंतर के लिए आवश्यक समस्याओं में। एक उन्नत तर्क रणनीति आम तौर पर एलएलएमएस में कमी है, जो कि एक केंद्रीय विधि को अस्वीकार करते हुए, काउंटरक्स नमूने द्वारा सबूत है। पर्याप्त वेतन पीढ़ी की अनुपस्थिति और प्रतिद्वंद्वियों का रोजगार उन्नत गणितीय तर्क में एलएलएम में बाधा डालता है, इसलिए औपचारिक चित्र आराधनात्मक सत्यापन और गणितीय अनुसंधान में उनकी विश्वसनीयता को कम कर रहा है।
एलएलएम में गणितीय तर्क को बेहतर बनाने के पिछले प्रयासों को दो सामान्य दृष्टिकोणों में वर्गीकृत किया गया है। पहला दृष्टिकोण, कृत्रिम समस्या पीढ़ी का भुगतान करती है, बीज गणित की समस्याओं द्वारा उत्पादित बड़े डेटासेट पर एलएलएम को प्रशिक्षित करती है। उदाहरण के लिए, विज़ार्डमथ विभिन्न स्तरों की समस्याओं का कारण बनने के लिए GPT -3.5 का उपयोग करता है। औपचारिक अग्रणी प्रमेय की तरह दूसरा दृष्टिकोण, ड्राफ्ट-स्केच-प्रावधानों और लीन-स्टार जैसी प्रूफ सिस्टम के साथ काम करने के लिए साबित होता है, LLM को LEAN 4 जैसे प्रूफ सिस्टम के साथ काम करने में मदद करता है, जो एक संरचित प्रमेय में LLMs की मदद करता है। यद्यपि इन दृष्टिकोणों में समस्या को हल करने की क्षमता बढ़ गई है, उनकी गंभीर सीमाएँ हैं। कृत्रिम प्रश्न पीढ़ी यादगार पैदा करती है और वास्तविक समझ नहीं है, मॉडल उपन्यास की समस्याओं से निपटने में विफलता के लिए अतिसंवेदनशील होते हैं। दूसरी ओर, औपचारिक पचेरिक प्रमेय-मूविंग तकनीक संरचित गणितीय भाषाओं में सीमित हैं जो उनके आवेदन को विभिन्न गणितीय संदर्भ तक सीमित करती हैं। ये सीमाएं वैकल्पिक पैटर्न की आवश्यकता दिखाती हैं – एक उदाहरण जो पैटर्न की मान्यता के खिलाफ वैचारिक समझ से संबंधित है।
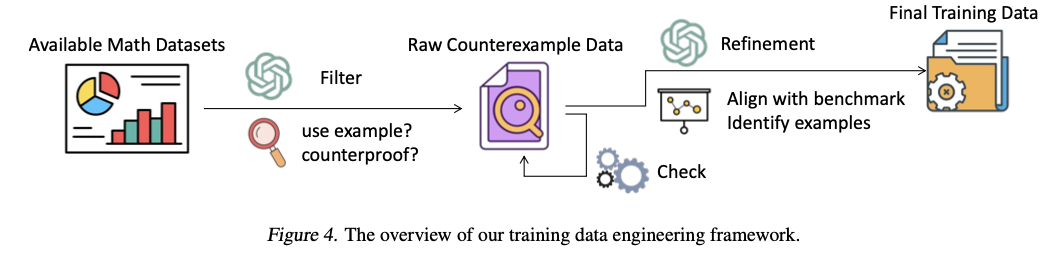
इन सीमाओं को दूर करने के लिए, काउंटरएक्स नमूना-आधारित गणितीय तर्क को एक बेंचमार्क प्रस्तुत किया गया है, जिसे काउंटरमैथ के रूप में जाना जाता है। बेंचमार्क विशेष रूप से एलएलएम के प्रमाण में काउंटरएक्सैम्पल्स के उपयोग का आकलन करने और विकसित करने के लिए डिज़ाइन किए गए हैं। नवाचारों में उच्च गुणवत्ता वाले बेंचमार्क, डेटा इंजीनियरिंग प्रक्रियाएं और पूर्ण मॉडल आकलन शामिल हैं। काउंटरमेथ में 1,216 गणितीय कथन होते हैं, जिनमें से प्रत्येक को अस्वीकार करने के लिए एक प्रतिद्वंद्वी की आवश्यकता होती है। समस्याएं विश्वविद्यालय की पाठ्यपुस्तकों से हाथ से हैं और विशेषज्ञों द्वारा विस्तारित हैं। एलएलएम के काउंटर-आधारित तर्क को बढ़ाने के लिए, प्रतिद्वंद्वी-आधारित तर्क उदाहरण प्राप्त करने के लिए, स्वचालित डेटा-एकत्रीकरण प्रक्रिया को लागू किया जाता है, गणितीय प्रमाण डेटा को फ़िल्टर और परिष्कृत किया जाता है। ओपनईएआई के ओ 1 मॉडल और फाइन-ट्यून्ड ओपन-सीज़ वेरिएंट जैसे परिष्कृत गणित एलएलएम की प्रभावशीलता की सख्ती से जांच की जाती है। विशिष्ट प्रमेय से एक उदाहरण-आधारित तर्क पर ध्यान केंद्रित करके, यह विधि गणितीय एलएलएम को प्रशिक्षित करने के लिए एक उपन्यास और अंडर-अंडर-अंडर-रूट शुरू करती है।

काउंटरमैथ का निर्माण चार मुख्य गणितीय शाखाओं के आधार पर किया जाता है: बीजगणित, टोपोलॉजी, वास्तविक विश्लेषण और कार्यात्मक विश्लेषण। डेटा मल्टी-स्टेप प्रक्रिया में बनाया गया है। सबसे पहले, गणितीय बयानों को पाठ्यपुस्तकों से एकत्र किया जाता है और OCR द्वारा संरचित डेटा में परिवर्तित किया जाता है। गणितज्ञ तब तार्किक प्रासंगिकता और सटीकता के लिए प्रत्येक समस्या की समीक्षा करते हैं और नोटिस करते हैं। चूंकि मूल डेटा चीनी में है, इसलिए पेशेवर अनुवाद किए जाते हैं, इसके बाद अतिरिक्त जांच होती है। इन-टास्क डेटा इंजीनियरिंग फ्रेमवर्क को काउंटरैक्स नमूना-आधारित तर्क के लिए स्वचालित रूप से प्रशिक्षण डेटा प्राप्त करने के लिए भी पेश किया जाता है। GPT -4O फ़िल्टरिंग और शुद्धिकरण तकनीक इस संरचना पर संबंधित साक्ष्य के लिए इस संरचना पर लागू होती है जैसे कि प्रूफनेट और नेचुरलप्रूफ। प्रत्येक साक्ष्य को यह सुनिश्चित करने के लिए स्पष्ट रूप से परिष्कृत किया जाता है कि प्रतियोगियों को शुद्ध किया जाता है ताकि एलएलएमएस काउंटर अधिक प्रभावी ढंग से एक्सेस-आधारित तर्क को सीख सके।
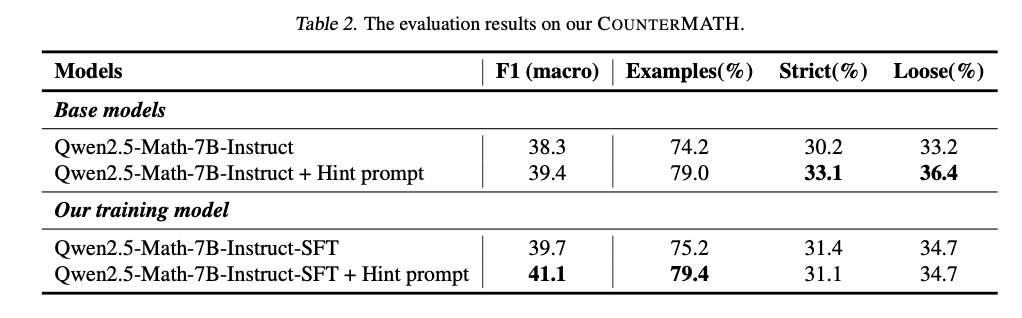
काउंटरमैथ पर परिष्कृत गणितीय एलएलएम का मूल्यांकन काउंटरैक्सल-आधारित तर्क के लिए एक महत्वपूर्ण दूरी दिखाता है। गहरी वैचारिक कमजोरी को दर्शाते हुए, अधिकांश मॉडल यह नहीं बताते हैं कि क्या डेल्स स्टेटमेंट सही है या गलत है। बेहतर और कार्यात्मक विश्लेषण बेहतर प्रदर्शन करता है, और टोपोलॉजी और वास्तविक विश्लेषण अभी भी उनके अमूर्त प्रकृति के कारण बहुत चुनौतीपूर्ण हैं, जो गणितीय क्षेत्रों में भी मिश्रित है। ओपन-सीरस मॉडल स्वामित्व वाले मॉडल से भी बदतर प्रदर्शन करते हैं, केवल कुछ में मध्यम वैचारिक तर्क हैं। काउंटरएक्स नमूना-आधारित डेटा के साथ फाइन-ट्यूनिंग, हालांकि, बेहतर निर्णय सटीकता और उदाहरण-आधारित तर्क के साथ, प्रदर्शन को महत्वपूर्ण रूप से बढ़ाता है। केवल 1,025 काउंटर-आधारित प्रशिक्षण नमूनों के साथ, एक अच्छा ट्यून मॉडल अपने बेसलाइन संस्करणों की तुलना में काफी बेहतर प्रदर्शन करता है, और वितरण के बाहर गणितीय परीक्षणों में एक मजबूत सामान्यीकरण है। नीचे दी गई तालिका 1 में दर्ज विस्तृत मूल्यांकन एफ 1 स्कोर और लॉजिक संगतता मैट्रिक्स के आधार पर ऑपरेशन की तुलना को दर्शाता है। QWEN2.5-MATH-72B-INSTRUCT ओपन-सन मॉडल में सबसे अच्छा (41.8 F1) करता है, लेकिन GPT-4 O (59.0 F1) और Openai O1 (60.1 F1) जैसे स्वामित्व वाले मॉडल के पीछे आता है। फाइन-ट्यूनिंग से महत्वपूर्ण लाभ होता है, QWEN2.5-MATH-7B I-I-INSTITUTE-SFT + सिग्नल 41.1 F1 का संकेत देता है, जो प्रतिरोध नमूना-आधारित प्रशिक्षण की प्रभावशीलता की पुष्टि करता है।

यह प्रस्तावित विधि काउंटरमैथ का प्रतिनिधित्व करती है, जो एक प्रतिद्वंद्वी आधारित लॉजिक बेंचमार्क है जिसे एलएलएम की काल्पनिक गणितीय क्षमताओं को बेहतर बनाने के लिए डिज़ाइन किया गया है। एक अच्छी तरह से ठीक समस्या सेट और स्वचालित डेटा शोधन प्रक्रिया के उपयोग से पता चलता है कि मौजूदा एलएलएम गहरा गणितीय तर्क में कुशल नहीं है, लेकिन काउंटरक्स नमूना-आधारित प्रशिक्षण के साथ बहुत बढ़ाया जा सकता है। इन परिणामों से संकेत मिलता है कि भविष्य के एआई अनुसंधान को वैचारिक समझ को बढ़ाने पर ध्यान केंद्रित करने की आवश्यकता है न कि एक्सपोज़र-आधारित शिक्षा। काउंटरक्स नमूने के तर्क को न केवल गणित में, बल्कि तर्क, एनसाइक्लोपीडिया में भी आवश्यक है।
जाँच करना कागज़। इस शोध के लिए सभी श्रेय इस परियोजना के शोधकर्ताओं को जाते हैं। इसके अलावा, हमें फॉलो करने के लिए स्वतंत्र महसूस करें ट्विटर और हमसे जुड़ने के लिए मत भूलना 75 k+ ml सबमिटेड।
। अनुशंसित रीडिंग- एलजी एआई रिसर्च नेक्सस प्रकाशित करता है: एक उन्नत प्रणाली एआई एजेंट एआई सिस्टम और डेटा अनुपालन मानकों को एक एआई डेटासेट में कानूनी चिंताओं को खत्म करने के लिए
Aswin AK MaviyechPost में एक परामर्श इंटर्न है। उन्हें खड़गपुर में भारतीय प्रौद्योगिकी में दोहरी डिग्री मिल रही है। यह डेटा अभिव्यक्तियों और पंखों और मशीन लर्निंग के बारे में उत्साही है, एक मजबूत शैक्षणिक पृष्ठभूमि और वास्तविक जीवन क्रॉस-डॉमन चुनौतियों को हल करने में अनुभव लाता है।



