

प्रबंध व्यक्तिगत रूप से पहचान योग्य जानकारी (पीआईआई) बड़ी भाषा मॉडल (LLM) गोपनीयता के लिए विशेष रूप से कठिन हैं। इस तरह के मॉडल को संवेदनशील डेटा के साथ भारी डेटासेट पर प्रशिक्षित किया जाता है, जिसके परिणामस्वरूप मेमोरी जोखिम और आकस्मिक घोषणाएं होती हैं। प्रबंधक पाई जटिल है क्योंकि डेटासेट को नई जानकारी के साथ लगातार अपडेट किया जाता है, और कुछ उपयोगकर्ता डेटा हटाने का अनुरोध कर सकते हैं। हेल्थकेयर जैसे क्षेत्रों में, पीआईआई को निकालना हमेशा संभव नहीं होता है। फाइन-ट्यूनिंग मॉडल विशिष्ट कार्यों के लिए अधिक संवेदनशील डेटा बनाए रखने के उच्च जोखिम में हैं। प्रशिक्षण के बाद भी, अवशिष्ट जानकारी हो सकती है, जिसके लिए tion के लिए विशेष तकनीकों की आवश्यकता होती है, और गोपनीयता संरक्षण एक कभी -कभी चुनौती है।
वर्तमान में, पीआईआई स्मृति को कम करने के तरीकों पर निर्भर करता है संवेदनशील डेटा को फ़िल्टर करने के लिए और मशीनजहां मॉडल विशिष्ट जानकारी के बिना पुनर्व्यवस्थित करते हैं। ये दृष्टिकोण मुख्य मुद्दों का सामना करते हैं, विशेष रूप से निरंतर डेटासेट में। ठीक-ट्यूनिंग मेमोरी का जोखिम अधिक है, और अनजाने में डेटा को अनजाने में हटाने के बजाय, अनजाने में डेटा को बाहर रखा जा सकता है। सदस्यता पूर्वानुमान हमले, जो विशिष्ट डेटा प्रशिक्षण को निर्धारित करने का प्रयास करते हैं, गंभीर चिंता का विषय है। जब मॉडल समय के साथ कुछ डेटा के बारे में भूल जाते हैं, तो वे छिपे हुए पैटर्न को बनाए रखते हैं जो जंग लगे हो सकते हैं। वर्तमान तकनीकों में प्रशिक्षण के दौरान याद रखने की पूरी समझ का अभाव है, जिससे गोपनीयता के जोखिमों को नियंत्रित करना मुश्किल हो जाता है।
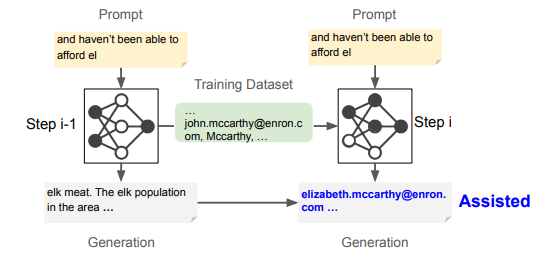
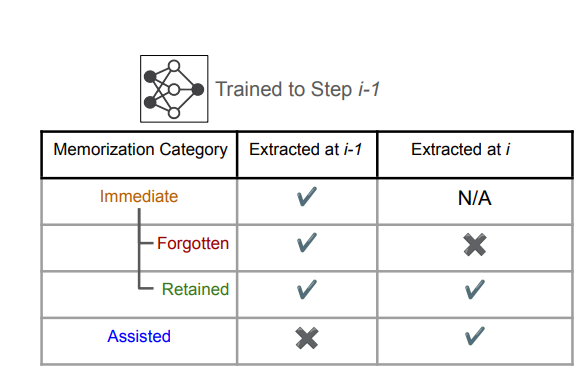
इन चुनौतियों को पार करने के लिए, शोधकर्ता पूर्वोत्तर विश्वविद्यालय, Google दीपमाइंड, और वाशिंगटन विश्वविद्यालय वाशिंगटन अधिसूचित “मददगार स्मरणसमय के साथ एलएलएम में व्यक्तिगत डेटा कैसे बनाए रखा जाता है, इसका विश्लेषण। वर्तमान तरीकों के विपरीत, इस बात पर ध्यान केंद्रित करते हुए कि क्या सूची की गई है, यह दृष्टिकोण यह जांचता है कि यह कब और क्यों होता है। शोधकर्ताओं ने विभिन्न प्रकार के PII स्मारक को वर्गीकृत किया-तत्काल, बनाए रखा, भूल गया, और मददगार– इन जोखिमों को बेहतर ढंग से समझने के लिए। परिणाम बताते हैं कि पीआईआई को तुरंत याद रखने की आवश्यकता नहीं है, लेकिन बाद में इसे ठीक किया जा सकता है, खासकर जब पिछली जानकारी के साथ नए प्रशिक्षण डेटा को ओवरलैप करें। यह वर्तमान डेटा रणनीति को कमजोर करता है जो लंबी -लंबी यादों के सुझावों को अनदेखा करता है।
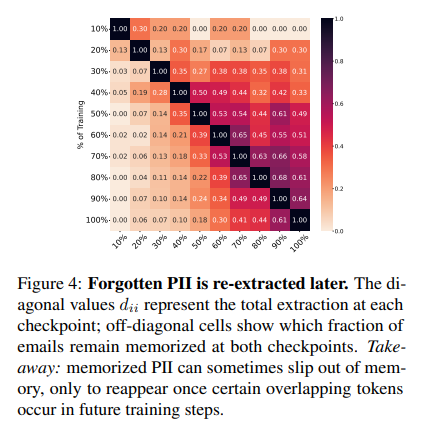
विभिन्न मॉडलों और डेटासेट के प्रयोगों के माध्यम से निरंतर प्रशिक्षण के दौरान फ्रेमवर्क पूरी तरह से पीआईआई मेमोरिज़ेशन को ट्रैक करता है। यह स्मृति और निष्कर्षण के जोखिमों पर विभिन्न प्रशिक्षण दृष्टिकोणों के प्रभाव का विश्लेषण करता है, यह दर्शाता है कि नए डेटा को जोड़ने से पीआईआई निष्कर्षण की संभावना बढ़ सकती है। एक व्यक्ति के लिए लिस्टिंग को कम करने का प्रयास कभी -कभी अनजाने में दूसरों के लिए जोखिम बढ़ाता है। शोधकर्ताओं ने मूल्यांकन किया जुर्माना, फिर सेऔर अज्ञात तकनीक जीवंत Gpt -2 -xl, लालमा 3 8 बी, और रत्नामा 2 बी संशोधित मॉडल पर प्रशिक्षित Vicaxt -2 और कानून का अंतराल अद्वितीय ईमेल के साथ डेटासेट। निष्कर्षण परीक्षणों ने यादों का मूल्यांकन किया, यह पता चलता है कि सहायक स्मृति में आ गया है 35.7% मामलों में, यह बताता है कि यह अपरिहार्य की तुलना में प्रशिक्षण गतिशीलता से प्रभावित था।
अधिक दस अलग -अलग PII प्रतिशत के साथ डेटासेट पर मॉडल। परिणामों ने पुष्टि की कि उच्चतर पाई सुपरलाइनर को शीर्ष-के नमूने के तहत निष्कर्षण में बढ़ाया गया था, जिससे सामग्री के लिए अधिक निष्कर्षण जोखिम हो गया। इसके अलावा, दोहरावदार अनियंत्रित ने इसे पेश किया “प्याज प्रभाव“रेक्टेड में पीआईआई को हटाने से पहले, अनमोल किए गए पीआईआई का rected उचित हो गया। इसने पुष्टि की कि प्रभाव के परिणाम यादृच्छिक भिन्नता के बजाय सीमावर्ती-सुधारित जानकारी के लिए व्यवस्थित प्रदर्शन में आते हैं। ये निष्कर्ष पीआईआई को जोड़ने और हटाने की चुनौतियों को प्रकाशित करते हैं, जो भाषा मॉडल में गोपनीयता रक्षा की जटिलताओं को दर्शाते हैं।
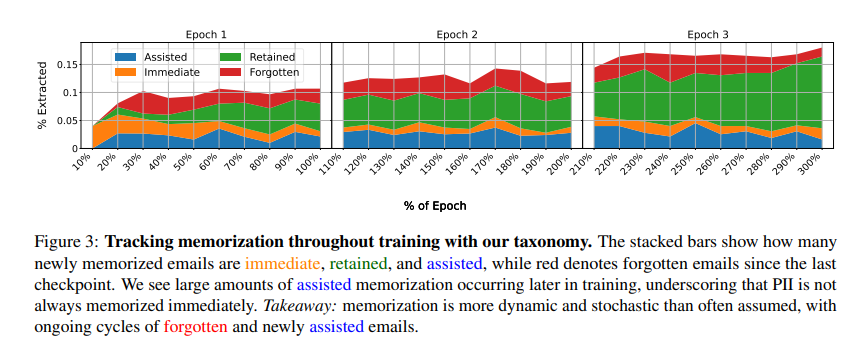
अंत में, प्रस्तावित विधि ने बड़ी भाषा मॉडल डेलेला में गोपनीयता के जोखिमों को उजागर किया, जिसमें दिखाया गया कि कैसे ठीक-ट्यूनिंग, पुनर्व्यवस्थित और गैरकानूनी अनजाने में पहचान योग्य जानकारी (पीआईआई) को उजागर कर सकते हैं। एडेड मेमोरी की पहचान की गई थी, जहां पीआईआई जो शुरू में ठीक नहीं किए गए थे, बाद में सुलभ हो सकते हैं। प्रशिक्षण डेटा ने पीआईआई में वृद्धि की है, और निष्कर्षण के जोखिम उठाए गए हैं, और कुछ पीआईआई को हटाकर अन्य जानकारी का अनावरण किया गया था। ये निष्कर्ष मशीन लर्निंग मॉडल में डेटा के लिए मजबूत सुरक्षा प्रदान करने, गोपनीयता-बचत तकनीकों में सुधार करने और अनौपचारिक तरीकों में सुधार करने के लिए समर्थन करते हैं।
जाँच करना कागज़। इस शोध के लिए सभी श्रेय इस परियोजना के शोधकर्ताओं को जाते हैं। इसके अलावा, हमें फॉलो करने के लिए स्वतंत्र महसूस करें ट्विटर और हमसे जुड़ने के लिए मत भूलना 80K+ एमएल सबमिटेड।
। अनुशंसित रीडिंग- एलजी एआई रिसर्च नेक्सस प्रकाशित करता है: एआई डेटासेट में कानूनी चिंताओं को खत्म करने के लिए एजेंट एआई सिस्टम और डेटा अनुपालन मानकों को एकीकृत करने वाला एक उन्नत प्रणाली
Divish मार्केटकपोस्ट में एक परामर्श इंटर्न है। वह खड़गपुर के एक भारतीय संगठन प्रौद्योगिकी एफ प्रौद्योगिकी से कृषि और खाद्य इंजीनियरिंग में BTech का पीछा कर रहे हैं। यह एक डेटा साइंस और मशीन लर्निंग उत्साही है जो इन प्रमुख तकनीकों को कृषि में एकीकृत करना चाहता है और चुनौतियों को हल करना चाहता है।
🚨 अनुशंसित ओपन-सीरस एआई प्लेटफॉर्म: ‘इंटेलिजेंट एक ओपन सोर्स मल्टी-एजेंट फ्रेमवर्क है जो कॉम्प्लेक्स वार्तालाप एआई सिस्टम का मूल्यांकन करता है’ (ईडी)


