


Модели крупных языков (LLM) полагаются на методы обучения подкреплению для расширения возможностей генерации реагирования. Одним из важных аспектов их разработки является моделирование вознаграждения, которое помогает в обучении моделей лучше соответствовать ожиданиям человека. Модели вознаграждений оценивают ответы на основе человеческих предпочтений, но существующие подходы часто страдают от субъективности и ограничений в фактической правильности. Это может привести к неоптимальной производительности, так как модели могут определить приоритетное беглость над точностью. Улучшение моделирования вознаграждения с помощью проверяемых сигналов правильности может помочь повысить надежность LLMS в реальных приложениях.
Основной проблемой в текущих системах моделирования вознаграждений является их тяжелая зависимость от человеческих предпочтений, которые по своей природе субъективны и подвержены предубеждениям. Эти модели предпочитают многословные ответы или те, у кого привлекательные стилистические элементы, а не объективно правильные ответы. Отсутствие систематических механизмов проверки в обычных моделях вознаграждения ограничивает их способность обеспечить правильность, делая их уязвимыми для дезинформации. Более того, ограничения, связанные с инструкциями, часто игнорируются, что приводит к выходам, которые не соответствуют точным требованиям пользователей. Крайне важно решить эти проблемы для повышения надежности и надежности ответов, сгенерированных AI.
Традиционные модели вознаграждений сосредоточены на обучении подкреплению на основе предпочтений, таком как обучение подкреплению с обратной связью с человека (RLHF). Хотя RLHF усиливает выравнивание модели, он не включает в себя проверку структурированной правильности. Некоторые существующие модели пытаются оценить ответы, основанные на когерентности и беглости, но не имеют надежных механизмов для проверки фактической точности или приверженности инструкциям. Альтернативные подходы, такие как проверка на основе правил, были изучены, но не широко интегрированы из-за вычислительных проблем. Эти ограничения подчеркивают необходимость в системе моделирования вознаграждения, которая объединяет человеческие предпочтения с подтверждаемыми сигналами правильности, чтобы обеспечить высококачественные языковые модели.
Исследователи из университета Цинхуа представили Моделирование агентского вознаграждения (ARM)новая система вознаграждений, которая объединяет обычные модели вознаграждений на основе предпочтений с подтверждаемыми сигналами правильности. Метод включает в себя агент вознаграждения по имени Вознаграждениечто повышает надежность вознаграждений, объединяя сигналы предпочтения человека с проверкой правильности. Эта система гарантирует, что LLMS генерируют ответы, которые являются предпочтительными пользователями и фактически точными. Интегрируя фактическую проверку и оценку, связанную с инструкциями, ARM обеспечивает более надежную структуру моделирования вознаграждений, которая уменьшает субъективные смещения и улучшает выравнивание модели.
А Вознаграждение Система состоит из трех основных модулей. А Маршрутизатор Анализирует пользовательские инструкции, чтобы определить, какие агенты проверки следует активировать на основе требований задачи. А Верификационные агенты Оценить ответы на два критических аспекта: фактическая правильность и приверженность жестким ограничениям. Агент фактической проверки перепроверяет информацию, используя как параметрические знания, так и внешние источники, гарантируя, что ответы хорошо сформированы и фактически обоснованы. Агент, подходящий для инструкций, обеспечивает соблюдение ограничений длины, формата и содержания путем анализа конкретных инструкций и проверки ответов на предопределенные правила. Последний модуль, Джаджеринтегрирует сигналы правильности и оценки предпочтений для вычисления общей оценки вознаграждения, балансируя субъективную обратную связь человека с объективной проверкой. Эта архитектура позволяет системе динамически выбирать наиболее подходящие критерии оценки для различных задач, обеспечивая гибкость и точность.
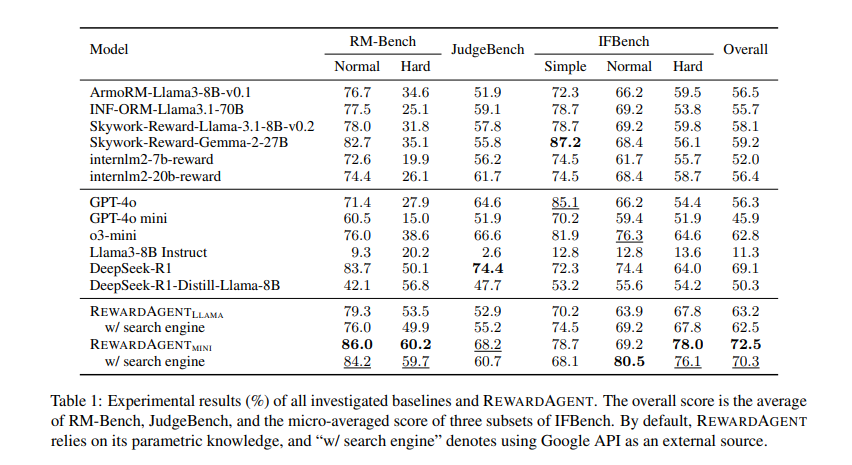
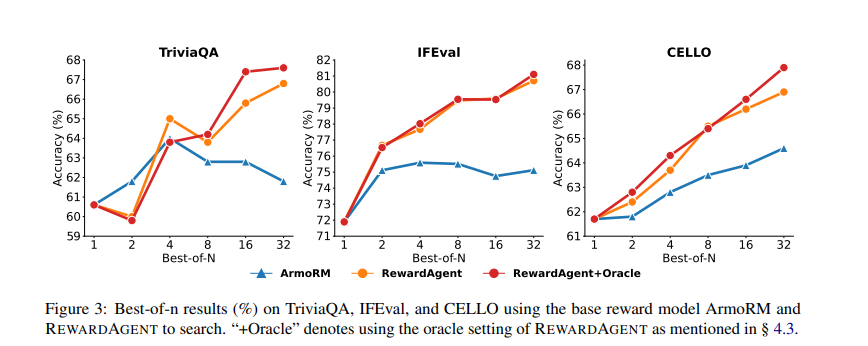
Обширные эксперименты продемонстрировали, что Вознаграждение Значительно превосходит традиционные модели вознаграждения. Он был оценен на критериях, таких как RM-Bench, Judgebench и Ifbenchдостижение превосходной производительности при выборе фактических и ограниченных ответов. В RM-Benchмодель достигла 76,0% Оценка точности с поисковой системой и 79,3% без, по сравнению с 71,4% Из обычных моделей вознаграждений. Система была дополнительно применена в реальном мире Лучший поиск Задачи, где он улучшил точность выбора ответа в нескольких наборах данных, включая Viriviaqa, Ifeval и виолончельПолем На ВитривиакаВ Вознаграждение достиг точно 68%превосходя модель базовой награды ArmormПолем Кроме того, модель была использована для построения пар предпочтений для Обучение оптимизации прямой предпочтения (DPO)где LLMS, обученные вознаграждению, сгенерированные парами предпочтений, превзошли те, которые обучались обычным аннотациям. В частности, модели, обученные этим методом, показали Улучшения в фактических задачах, основанных на вопросах и обучении инструкциямдемонстрируя его эффективность при уточнении выравнивания LLM.
Исследование учитывает решающее ограничение в моделировании вознаграждения путем интеграции проверки правильности с оценкой предпочтений человека. Вознаграждение Улучшает надежность моделей вознаграждения и позволяет более точным и управляемым ответам LLM. Этот подход прокладывает путь для дальнейших исследований по включению дополнительных проверяемых сигналов правильности, в конечном итоге способствуя разработке более надежных и способных систем ИИ. Будущая работа может расширить объем верификационных агентов, чтобы охватить более сложные измерения правильности, гарантируя, что моделирование вознаграждения продолжает развиваться с растущими требованиями приложений, управляемых ИИ.
Проверить бумага и GitHub PageПолем Весь кредит на это исследование направлено на исследователей этого проекта. Кроме того, не стесняйтесь следить за нами Twitter И не забудьте присоединиться к нашему 80K+ ML SubredditПолем
🚨 Рекомендуемое чтение AI Research выпускает Nexus: расширенная система интеграции системы ИИ и стандартов соответствия данными для решения юридических проблем в наборах данных AI
Нихил – стажер консультант в Marktechpost. Он получает интегрированную двойную степень в области материалов в Индийском технологическом институте, Харагпур. Нихил является энтузиастом AI/ML, который всегда исследует приложения в таких областях, как биоматериалы и биомедицинская наука. С большим опытом в области материальной науки, он изучает новые достижения и создает возможности для внесения вклад.
🚨 Рекомендуемая платформа искусственного интеллекта с открытым исходным кодом: «Intellagent-это многоагентная структура с открытым исходным кодом для оценки сложной разговорной системы ИИ» (PROMOTED)


