


Понимание Видео с ИИ Требуется эффективная обработка последовательностей изображений. Основной проблемой в текущих моделях ИИ на основе видео является их неспособность обрабатывать видео в качестве непрерывного потока, пропуская важные детали движения и нарушая непрерывность. Отсутствие временного моделирования предотвращает изменения трассировки; Поэтому события и взаимодействия частично неизвестны. Длинные видео также усложняют процесс, с высокими вычислительными затратами и требующими методов, таких как пропуск кадров, которые теряют ценную информацию и снижают точность. Перекрытие между данными в рамках также не сжимает хорошо, что приводит к избыточности и потери ресурсам.
В настоящее время видеоязычные модели рассматривают видео как статические кадры с Изображение кодеры и зрительные проекторычто сложно представлять движение и непрерывность. Языковые модели должны самостоятельно выводить временные отношения, что приводит к частичному пониманию. Подбадрирование кадров снижает вычислительную нагрузку за счет удаления полезных деталей, влияя на точность. Методы восстановления токенов, такие как рекурсивное сжатие кэша KV и выбор кадров, добавляют сложность без значительного улучшения. Хотя расширенные видеокодеры и методы объединения помогают, они остаются неэффективными и не масштабируемыми, что делает длинные видео-обработки вычислительно интенсивно.
Чтобы решить эти проблемы, исследователи из НвидияВ Университет РутгерсаВ UC БерклиВ ГраньВ Нанкинский университети Кайст предложенный Шторм (Сокращение пространственно -временного токена для мультимодальных LLMS), архитектура временного проектора на основе Мамбы для эффективной обработки длинных видео. В отличие от традиционных методов, когда временные отношения выводятся отдельно на каждом видео кадре, а языковые модели используются для вывода временных отношений, Шторм Добавляет временную информацию на уровне Video Tokens, чтобы устранить избыточность вычислений и повысить эффективность. Модель улучшает видео -представления с помощью двунаправленного пространственно -временного механизма сканирования, смягчая бремя временных рассуждений от LLM.
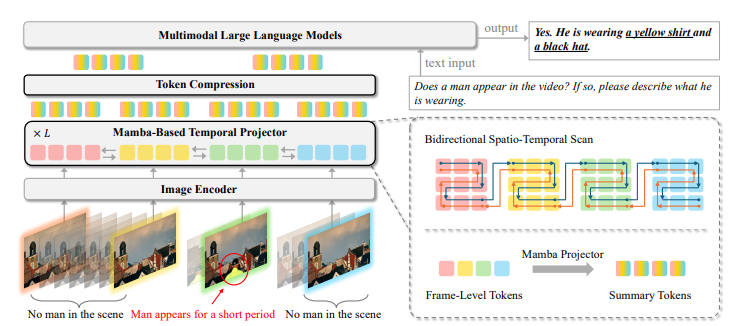
Структура использует Мамба слои Чтобы улучшить временное моделирование, включение двунаправленного модуля сканирования для захвата зависимостей между пространственными и временными измерениями. А Временный энкодер Обрабатывает изображение и видео входы по -разному, выступая в качестве пространственного сканера для изображений для интеграции глобального пространственного контекста и как пространственно -временного сканера для видео для захвата временной динамики. Во время обучения методы сжатия токена повысили эффективность вычислительной техники, сохраняя при этом необходимую информацию, позволяя сделать вывод на одном Графический процессорПолем Без обучения токеновой субботней дискретизации во время теста снижает вычислительное бремя при сохранении важных временных деталей. Этот метод способствовал эффективной обработке длинных видеороликов, не требуя специализированного оборудования или глубоких адаптаций.
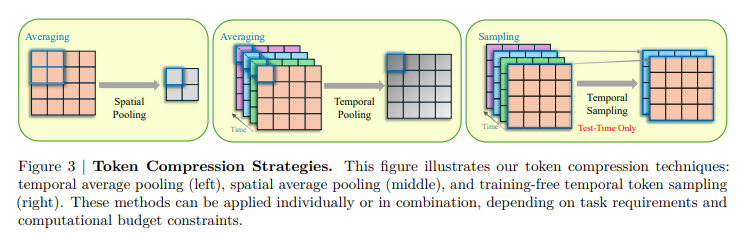
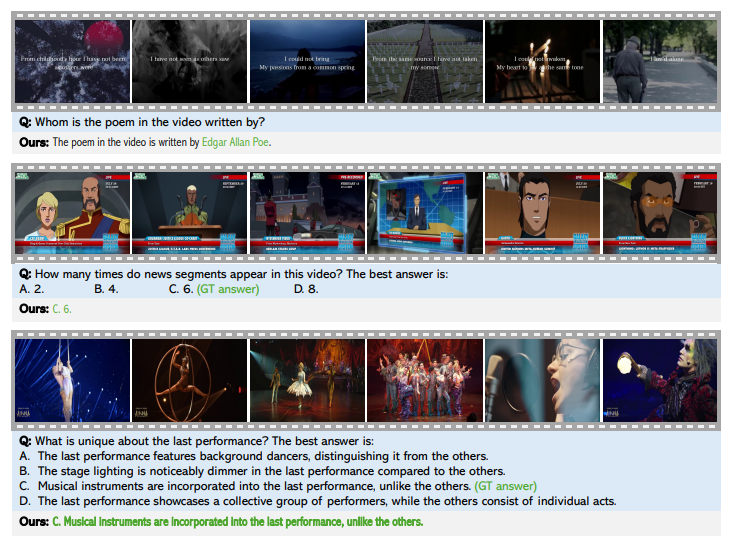
Эксперименты были проведены для оценки Шторм модель для понимания видео. Обучение проводилось с использованием предварительно обученного Сиглип модели, с временным проектором, введенным посредством случайной инициализации. Процесс связан два этапы: стадия выравниваниягде были заморожены изображение энкодер и LLM, в то время как только височный проектор обучался с использованием пар изображений. Наблюдаемая сценария (Суп) с разнообразным набором данных из 12,5 миллионов образцов, включая текст, текстовый текст и видео-текст. Методы сжатия токена, включая временное и пространственное объединение, снижение вычислительной нагрузки. Последняя модель была оценена на давно-видео-критериях, таких как ЭгошемаВ MVBenchВ MLVUВ Longvideobenchи Видеомас производительностью, сравниваемой с другими видео LLM.
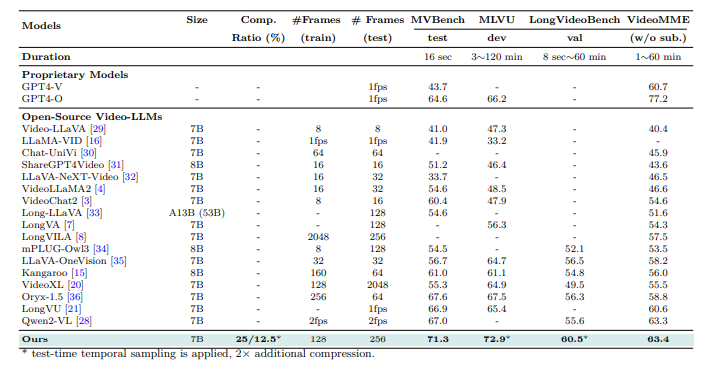
После оценки Шторм превзошел существующие модели, достигнув самых современных результатов по критериям. Модуль MAMBA повысил эффективность, сжав визуальные токены, сохраняя ключевую информацию, сокращая время вывода до до 65,5%Полем Временное объединение лучше всего работало над длинными видео, оптимизируя производительность с небольшим количеством жетонов. Шторм также работал намного лучше, чем базовая линия Вила модель, особенно в задачах, которые включали понимание глобального контекста. Результаты подтвердили значимость мамбы для оптимизированного сжатия токенов, при этом повышение производительности повышается с длиной видео 8 к 128 рамы.
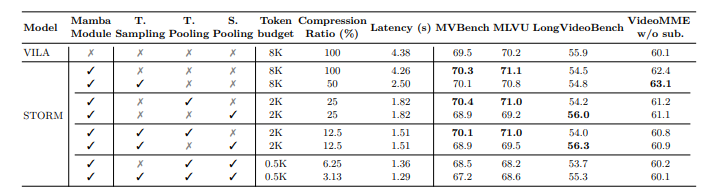
Таким образом, предлагаемая модель шторма улучшила длинное видео-понимание с использованием височного энкодера на основе Мамбы и эффективного снижения токена. Это позволило сильно сжать без потери ключевой височной информации, записывая современные характеристики на тесных показателях с длинными видео, сохраняя при этом низкие вычисления. Метод может выступить в качестве базовой линии для будущих исследований, способствующих сжатию токенов, мультимодальному выравниванию и развертыванию реального мира для повышения точности и эффективности модели на языке видео.
Проверить бумага. Весь кредит на это исследование направлено на исследователей этого проекта. Кроме того, не стесняйтесь следить за нами Twitter И не забудьте присоединиться к нашему 80K+ ML SubredditПолем
🚨 Познакомьтесь с «Партаном»: разговорная структура ИИ, на первом месте LLM, предназначенную для того, чтобы предоставить разработчикам контроль и точность, которые им нужны, по сравнению с их агентами по обслуживанию клиентов AI, используя поведенческие руководящие принципы и надзор за время выполнения. 🔧 🎛 Он работает с использованием простого в использовании CLI 📟 и нативных SDK клиента в Python и TypeScript 📦.
Divyesh – стажер консалтинга в Marktechpost. Он преследует BTECH в области сельского хозяйства и продовольственной инженерии от Индийского технологического института, Харагпур. Он является любителем науки о данных и машинного обучения, который хочет интегрировать эти ведущие технологии в сельскохозяйственную область и решить проблемы.
Парган: строите надежные агенты, обращенные к клиенту AI с LLMS 💬 ✅ (повышен)

