


Обучение полезные функции из большого количества немеченых изображений важно, и такие модели, как Дино и DINOV2 предназначены для этого. Эти модели хорошо работают для таких задач, как классификация изображений и сегментация, но их процесс обучения сложный. Ключевой проблемой является избегание обезболивания представления, где модель производит один и тот же выход для разных изображений. Многие настройки должны быть тщательно скорректированы, чтобы предотвратить это, делая тренировку нестабильной и трудной для управления. DINOV2 пытается решить это, непосредственно используя отрицательные образцы, но обучающая установка остается сложной. Из -за этого сложно улучшить эти модели или их использование в новых областях, даже если их ученые особенности очень эффективны.
В настоящее время методы обучения изображений полагаются на сложные и нестабильные тренировочные установки. Методы, как SimclrВ СимсиамВ ВикВ Мокои Биол Попытка обнаружить полезные представления, но сталкиваться с различными проблемами. Simclr и Моко Требовать больших размеров партий и явных отрицательных образцов, что делает их вычислительно дорогими. Simsiam и Byol стараются избежать коллапса, изменяя градиентную структуру, которая требует тщательной настройки. Vicreg наказывает выравнивание функций и ковариацию, но не решает дисперсию функций эффективно. Такие методы, как I-JEPA и C-JEPA, фокусируются на обучении на основе патчей, но добавляют больше сложности. Эти методы борются за сохранение простоты, стабильности и эффективности, усложнения тренировок и ограничения гибкости.
Чтобы решить сложности Дино, исследователи из Калифорнийского университета в Беркли, Transcengram, Microsoft Research и HKU предложили Симдино и Simdinov2Полем Эти модели упрощают обучение путем включения термина регуляризации скорости кодирования в функцию потерь, которая предотвращает коллапс представления и устраняет необходимость в тяжелой пост-обработке и настройке гиперпараметров. Предотвращая ненужный выбор дизайна, Simdino улучшает стабильность и эффективность обучения. Simdinov2 повышает производительность, обрабатывая небольшие и большие области изображения без применения высокоразмерных преобразований и устранения парадигмы учителя-ученика, что делает метод более надежным и эффективным, чем существующие методы.
Эта структура максимизирует обучение путем непосредственного контроля представлений функций, чтобы быть полезными на протяжении всего обучения без сложных адаптаций. Термин скорости кодирования дает модели структурированные и информативные функции, что приводит к лучшему обобщению и производительности задачи по течению. Это упрощает тренировочный трубопровод и удаляет Парадигма учителя-ученикаПолем Симдино снижает вычислительные накладные расходы, сохраняя при этом высококачественные результаты, что делает его более эффективной альтернативой для самоуверенного обучения в задачах зрения.

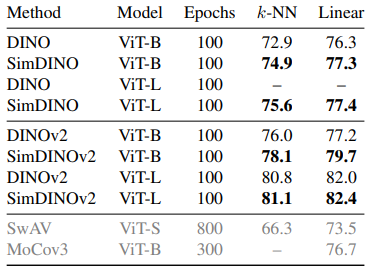
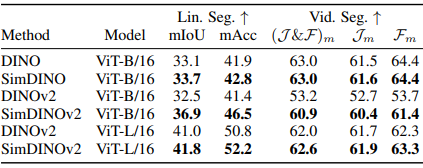
Исследователи оценили Simdino и Simdinov2 против Dino и Dinov2 на ImageNet–1KВ Coco Val2017В ADE20Kи Дэвис–2017 с использованием Vit Архитектуры с размером патча 16Полем Симдино достиг более высокой K-NN и линейной точности при сохранении стабильных тренировок, в отличие от Dino, что показало падения производительности. Симдино превзошел дино на Coco Val2017, используя Маскат в обнаружении и сегментации объекта. Для семантической сегментации на ADE20KВ Simdinov2 улучшен DINOV2 к 4.4 Миу на Vit-b. На Davis-2017 варианты Simdino работали лучше, хотя Dinov2 и Simdinov2 снизили свои предшественники из-за чувствительности к оценке. Тесты стабильности показали, что DINO был более чувствительным к гиперпараметрам и вариациям наборов данных, расходящимися на Vit-L, в то время как Simdino оставался надежным, значительно превосходя DINO при обучении на Coco Train 2017.
В заключение, предлагаемый Симдино и Simdinov2 Модели упростили сложный выбор дизайна DINO и DINOV2, внедрив термин регуляризации, связанный с кодированием, делая учебные трубопроводы более стабильными и надежными при повышении производительности в нижестоящих задачах. Эти модели улучшили Парето по сравнению с их предками, устраняя ненужные сложности, демонстрируя преимущества непосредственной работы с компромиссами в самоуверенном зрении. Эффективная структура устанавливает основу для анализа геометрической структуры самоотверженных потерь обучения и оптимизации модели без самоотраживания. Эти идеи также могут быть применены к другим самоотверженным моделям обучения, чтобы сделать обучение более стабильным и эффективным, что делает Simdino сильной отправной точкой для разработки лучших моделей глубокого обучения.
Проверить бумага. Весь кредит на это исследование направлено на исследователей этого проекта. Кроме того, не стесняйтесь следить за нами Twitter И не забудьте присоединиться к нашему 80K+ ML SubredditПолем
🚨 Рекомендуемое чтение AI Research выпускает Nexus: расширенная система интеграции системы ИИ и стандартов соответствия данными для решения юридических проблем в наборах данных AI
Divyesh – стажер консалтинга в Marktechpost. Он преследует BTECH в области сельского хозяйства и продовольственной инженерии от Индийского технологического института, Харагпур. Он является любителем науки о данных и машинного обучения, который хочет интегрировать эти ведущие технологии в сельскохозяйственную область и решить проблемы.
🚨 Рекомендуемая платформа искусственного интеллекта с открытым исходным кодом: «Intellagent-это многоагентная структура с открытым исходным кодом для оценки сложной разговорной системы ИИ» (PROMOTED)


