


Эффективное сравнение языковых моделей требует систематического подхода, который объединяет стандартизированные тесты с конкретным тестированием. Это руководство проводит вас через процесс оценки LLMS для принятия обоснованных решений для ваших проектов.
Шаг 1: Определите свои цели сравнения
Прежде чем погрузиться в тесты, четко установите, что вы пытаетесь оценить:
🎯 Ключевые вопросы, чтобы ответить:
- Какие конкретные возможности наиболее важны для вашего приложения?
- Вы расставляете приоритет точности, скорости, стоимости или специализированных знаний?
- Вам нужны количественные показатели, качественные оценки или оба?
Совет профессионала: Создайте простую рубрику с взвешенной важности для каждой возможности, относящейся к вашим варианту использования.
Шаг 2: Выберите соответствующие тесты
Различные тесты измеряют различные возможности LLM:
Общее понимание языка
- MMLU (Массовое многозадачное понимание языка)
- ШЛЕМ (Целостная оценка языковых моделей)
- Большой-пластин (Помимо имитационного эталона игры)
Рассуждение и решение проблем
- GSM8K (Математика начальной школы 8K)
- Математика (Математическая способность эфуристики)
- Логика (Логические рассуждения)
Кодирование и технические способности
- Гуманевал (Синтез функции Python)
- MBPP (В основном основное программирование Python)
- DS-1000 (Проблемы науки о данных)
Правдивость и фактическая
- Правдифка (Правдивый вопрос ответа)
- FactScore (Фактическая оценка)
Инструкция следующая
- Alpaca Eval
- Mt-Bench (Многообразовательный эталон)
Оценка безопасности
- Красная команда Антропика набор данных
- Безопасность
Совет профессионала: Сосредоточьтесь на критериях, которые соответствуют вашему конкретному варианту использования, а не пытаются проверить все.
Шаг 3: Просмотрите существующие таблицы лидеров
Сэкономьте время, проверив опубликованные результаты на установленных таблицах лидеров:
Рекомендуемые таблицы лидеров
Шаг 4: Настройка среды тестирования
Обеспечить справедливое сравнение с последовательными условиями испытаний:
Контрольный список среды
- Используйте идентичное оборудование для всех тестов, когда это возможно
- Контроль по температуре, токенам максимума и другим параметрам генерации
- Документальные версии API или конфигурации развертывания
- Стандартизировать форматирование и инструкции по приглашению
- Используйте те же критерии оценки по моделям
Совет профессионала: Создайте файл конфигурации, который документирует все ваши параметры тестирования для воспроизводимости.
Шаг 5: Используйте структуры оценки
Несколько структур могут помочь автоматизировать и стандартизировать процесс оценки:
Популярные рамки оценки
| Рамки | Лучше всего для | Установка | Документация |
| Lmsys Chatbot Arena | Человеческие оценки | Интернет | Связь |
| Оценка Лэнгхейна | Тестирование рабочего процесса | PIP установить Langchain-Eval | Связь |
| Eleutherai LM Harning Harning | Академические тесты | PIP установить LM-Eval | Связь |
| Deepeval | ЕДИНЦИОННЫЕ Тестирование | PIP установить DeepEval | Связь |
| Ramplefoo | Быстрое сравнение | npm install -g recafffoo | Связь |
| Труленс | Анализ обратной связи | PIP установить Trulens-Eval | Связь |

Шаг 6: Реализация пользовательских испытаний на оценку
Выйдите за пределы стандартных тестов с тестами, адаптированными к вашим потребностям:
Пользовательские категории тестирования
- Специфичные для домена знания тесты, относящиеся к вашей отрасли
- Реальные подсказки Из ваших ожидаемых вариантов использования
- Крайные случаи это раздвигает границы модельных возможностей
- A/B Сравнения с одинаковыми входами в разных моделях
- Пользовательский тестирование с представителями пользователей
Совет профессионала: Включите как «ожидаемые» сценарии, так и сценарии «стресс -тест», которые бросают вызов моделям.
Шаг 7: анализировать результаты
Преобразовать необработанные данные в действенные идеи:
Методы анализа
- Сравните необработанные оценки по критериям
- Нормализовать результаты для учета различных масштабов
- Рассчитать пробелы в процентах
- Определите закономерности сильных и слабых сторон
- Рассмотрим статистическую значимость различий
- Производительность сюжета в разных областях возможностей
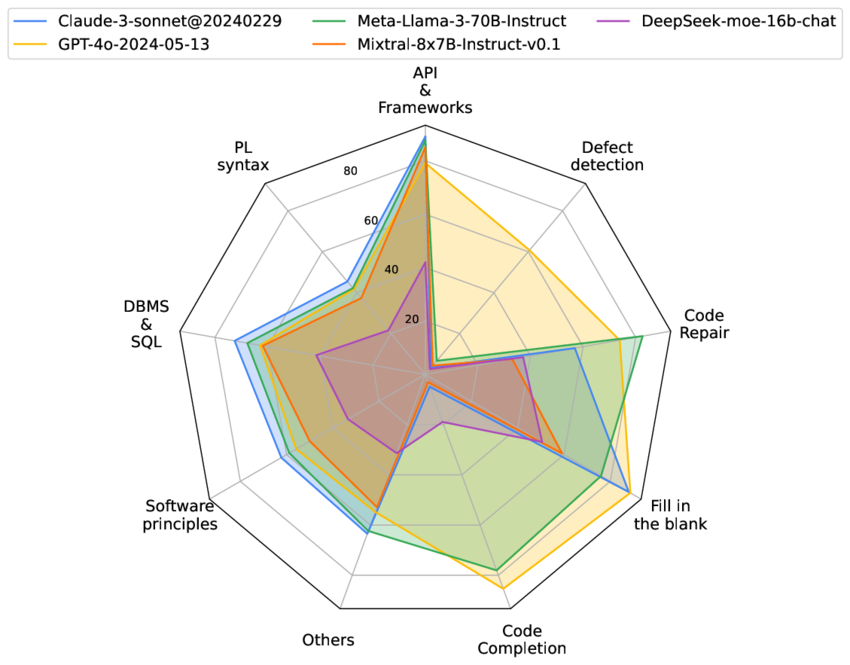
Шаг 8: Документируйте и визуализируйте выводы
Создайте четкую, сканируемую документацию ваших результатов:
Шаблон документации

Шаг 9: Рассмотрим компромиссы
Посмотрите за пределы необработанной производительности, чтобы сделать целостную оценку:
Ключевые компромиссные факторы
- Стоимость против производительности – Стоит ли улучшение цены?
- Скорость против точности -Вам нужны ответы в реальном времени?
- Контекст окна – Может ли он обрабатывать длину вашего документа?
- Специализированные знания – Это преуспевает в вашем домене?
- Надежность API -Служба стабильна и хорошо поддерживается?
- Конфиденциальность данных – Как обрабатываются ваши данные?
- Обновление частоты – Как часто модель улучшается?
Совет профессионала: Создайте взвешенную матрицу решений, которая во всех соответствующих соображениях.
Шаг 10: принять обоснованное решение
Переведите свою оценку в действие:
Окончательное процесс принятия решения
- Ранные модели на основе производительности в приоритетных областях
- Рассчитайте общую стоимость владения в течение ожидаемого периода использования
- Рассмотрим требования к усилиям и интеграции в реализацию
- Пилотный тест ведущего кандидата с помощью подмножества пользователей или данных
- Установить текущие процессы оценки для мониторинга производительности
- Задокументируйте свое обоснование решения для будущего справки
Нихил – стажер консультант в Marktechpost. Он получает интегрированную двойную степень в области материалов в Индийском технологическом институте, Харагпур. Нихил является энтузиастом AI/ML, который всегда исследует приложения в таких областях, как биоматериалы и биомедицинская наука. С большим опытом в области материальной науки, он изучает новые достижения и создает возможности для внесения вклад.
🚨 Рекомендуемая Платформа ИИ с открытым исходным кодом: «Intellagent-это многоагентная структура с открытым исходным кодом для оценки сложной разговорной системы ИИ» (PROMOTED)


