


Большие языковые модели (LLMS) Создайте текст шаг за шагом, что ограничивает их способность планировать задачи, требующие нескольких шагов рассуждений, таких как структурированное письмо или решение проблем. Это отсутствие долгосрочного планирования влияет на их согласованность и принятие решений в сложных сценариях. Некоторые подходы оценивают различные альтернативы, прежде чем сделать выбор, что повышает точность прогнозирования. Тем не менее, они имеют более высокие вычислительные затраты и склонны к ошибкам, если будущие прогнозы были неверными.
Очевидные алгоритмы поиска, такие как Поиск дерева Монте -Карло (MCT) и Лучший поиск очень популярны в планировании ИИ и принятии решений, но отсутствуют присущие неизменные ограничения. Они используют повторное моделирование будущего, с растущими затратами на вычисление и делают их непригодными для систем в реальном времени. Они также зависят от модели стоимости для оценки каждого состояния, которое, если неверно, распространяет ошибку вдоль поиска. Поскольку более длительные прогнозы создают больше ошибок, эти ошибки нарастают и снижают точность решения. Это особенно проблематично в сложных задачах, требующих долгосрочного планирования, когда становится сложно поддерживать точное предвидение, что приводит к низким результатам.
Чтобы смягчить эти проблемы, исследователи из Университет Гонконга, Шанхайский университет Цзиотонг, Арк -лаборатория Huawei Noah, и Шанхайская лаборатория AI предложенный DiffusearchПолем Эта дискретная структура на основе диффузии устраняет явные алгоритмы поиска, такие как МСПолем Вместо того, чтобы полагаться на дорогостоящие процессы поиска, Diffusearch обучает политике напрямую прогнозировать и использовать будущие представления, итеративно уточняя прогнозы, используя диффузионные модели. Интеграция мировой модели и политики в единую структуру снижает вычислительные накладные расходы, одновременно повышая эффективность и точность в долгосрочном планировании.
Структура обучает модель, используя контролируемое обучение, используя Stockfish в качестве оракула для маркировки доски из шахматных игр. Разные будущие представления исследуются, причем метод действий (S-ASA) выбран для простоты и эффективности. Вместо того, чтобы непосредственно прогнозировать будущие последовательности, модель использует дискретное диффузионное моделирование, применяя самопричастое и итеративное денирование для постепенного улучшения прогнозов действий. Diffusearch избегает дорогостоящей маргинализации в будущих состояниях во время вывода путем непосредственного отбора проб из обученной модели. Легкая первая стратегия декодирования приоритет более предсказуемым токенам для обозначения, повышения точности.
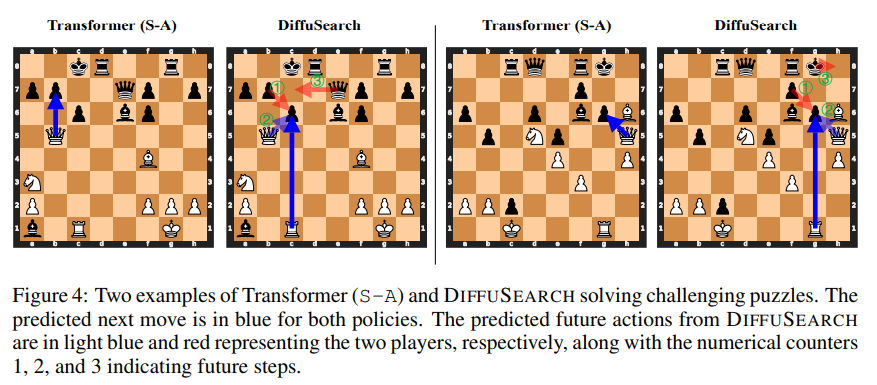
Исследователи оценили Diffusearch Против трех базовых показателей на основе трансформаторов: модели состояния (SA), стоимость состояний (SV) и акция (SA-V), обученные с использованием поведенческого клонирования, принятия решений на основе стоимости и сравнения судебных исков, соответственно. Использование набора данных из 100 тыс. Кематических игр, с государствами, кодируемыми в формате FEN и действиях в нотации UCI, они реализовали модели на основе GPT-2 с оптимизатором ADAM, скорость обучения 3E-4, размер партии 1024, 8-слойную архитектуру (7M Параметры), горизонт 4 и диффузионные временные эк. Внутренний турнир 6000 игр. Diffusearch опередил SA на 653 ELO и 19% в точности действия и превышал SA-V, несмотря на то, что в 20 раз меньше записей данных. Дискретная диффузия с линейной λt достигла самой высокой точности (41,31%), превосходное авторегрессивное и гауссовое методы. Diffusearch сохранил прогнозирующую способность в будущих шагах, хотя точность снизилась по шагам, а производительность улучшилась с большим количеством слоев внимания и утонченным декодированием. Расположенный как неявный метод поиска, он продемонстрировал конкурентоспособность с явными подходами на основе MCTS.
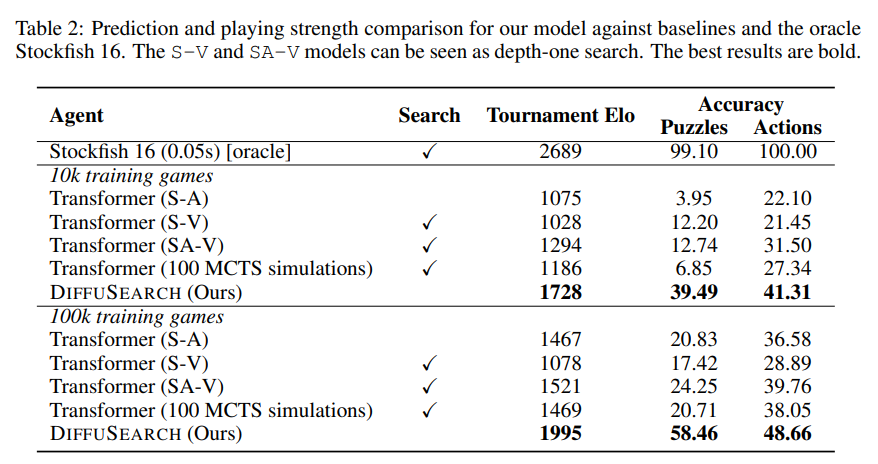
Таким образом, предложенная модель установила, что неявный поиск через дискретную диффузию может эффективно заменить явный поиск и улучшить принятие шахматных решений. Модель превзошла политику без поиска и явную политику и продемонстрировала свою потенциал для изучения будущих имитационных стратегий. Несмотря на использование внешнего Oracle и ограниченный набор данных, модель указывала на будущие возможности для улучшения за счет самостоятельного и моделирования с длинным контекстом. В целом, этот метод может быть применен для улучшения прогнозирования следующего ток в языковых моделях. В качестве отправной точки для дальнейшего расследования он является основой для расследования неявного поиска в планировании ИИ и принятии решений.
Проверить бумага и страница Github. Весь кредит на это исследование направлено на исследователей этого проекта. Кроме того, не стесняйтесь следить за нами Twitter И не забудьте присоединиться к нашему 80K+ ML SubredditПолем
🚨 Рекомендуемое чтение AI Research выпускает Nexus: расширенная система интеграции системы ИИ и стандартов соответствия данными для решения юридических проблем в наборах данных AI
Divyesh – стажер консалтинга в Marktechpost. Он преследует BTECH в области сельского хозяйства и продовольственной инженерии от Индийского технологического института, Харагпур. Он является любителем науки о данных и машинного обучения, который хочет интегрировать эти ведущие технологии в сельскохозяйственную область и решить проблемы.
🚨 Рекомендуемая платформа искусственного интеллекта с открытым исходным кодом: «Intellagent-это многоагентная структура с открытым исходным кодом для оценки сложной разговорной системы ИИ» (PROMOTED)

